- Wahoo's largest bike computer is the fitness accessory I didn't know I needed
- Thanks to AI, the data reckoning has arrived
- YouTube celebrates 20 years with new features, cool tricks, and some truly mind-blowing stats
- Here's how you can try Audible for $1 per month
- How to set up remote desktop access on your Linux computers

Uncompromised Ethernet: Performance and Benchmarking for AI/ML Fabric

Today, we’re exploring how Ethernet stacks up against InfiniBand in AI/ML environments, focusing on how Cisco Silicon One™ manages network congestion and enhances performance for AI/ML workloads. This post emphasizes the importance of benchmarking and KPI metrics in evaluating network solutions, showcasing the Cisco Zeus Cluster equipped with 128 NVIDIA® H100 GPUs and cutting-edge congestion management technologies like dynamic load balancing and packet spray.
Networking standards to meet the needs of AI/ML workloads
AI/ML training workloads generate repetitive micro-congestion, stressing network buffers significantly. The east-to-west GPU-to-GPU traffic during model training demands a low-latency, lossless network fabric. InfiniBand has been a dominant technology in the high-performance computing (HPC) environment and lately in the AI/ML environment.
Ethernet is a mature alternative, with advanced features that can address the rigorous demands of the AI/ML training workloads and Cisco Silicon One can effectively execute load balancing and manage congestion. We set out to benchmark and compare Cisco Silicon One versus NVIDIA Spectrum-X™ and InfiniBand.
Evaluation of network fabric solutions for AI/ML
Network traffic patterns vary based on model size, architecture, and parallelization techniques used in accelerated training. To evaluate AI/ML network fabric solutions, we identified relevant benchmarks and key performance indicator (KPI) metrics for both AI/ML workload and infrastructure teams, because they view performance through different lenses.
We established comprehensive tests to measure performance and generate metrics specific to AI/ML workload and infrastructure teams. For these tests, we used the Zeus Cluster, featuring dedicated backend and storage with a standard 3-stage leaf-spine Clos fabric network, built with Cisco Silicon One–based platforms and 128 NVIDIA H100 GPUs. (See Figure 1.)
We developed benchmarking suites using open-source and industry-standard tools contributed by NVIDIA and others. Our benchmarking suites included the following (see also Table 1):
- Remote Direct Memory Access (RDMA) benchmarks—built using IBPerf utilities—to evaluate network performance during congestion created by incast
- NVIDIA Collective Communication Library (NCCL) benchmarks, which evaluate application throughput during training and inference communication phase among GPUs
- MLCommons MLPerf set of benchmarks, which evaluates the most understood metrics, job completion time (JCT) and tokens per second by the workload teams
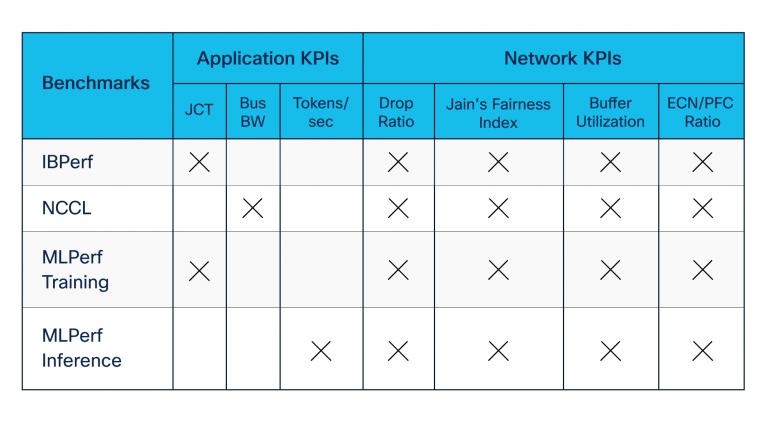
Legend:
JCT = Job Completion Time
Bus BW = Bus bandwidth
ECN/PFC = Explicit Congestion Notification and Priority Flow Control
NCCL benchmarking against congestion avoidance features
Congestion builds up during the back propagation stage of the training process, where a gradient sync is required among all the GPUs participating in training. As the model size increases, so does the gradient size and the number of GPUs. This creates massive micro-congestion in the network fabric. Figure 2 shows results of the JCT and traffic distribution benchmarking. Note how Cisco Silicon One supports a set of advanced features for congestion avoidance, such as dynamic load balancing (DLB) and packet spray techniques, and Data Center Quantized Congestion Notification (DCQCN) for congestion management.
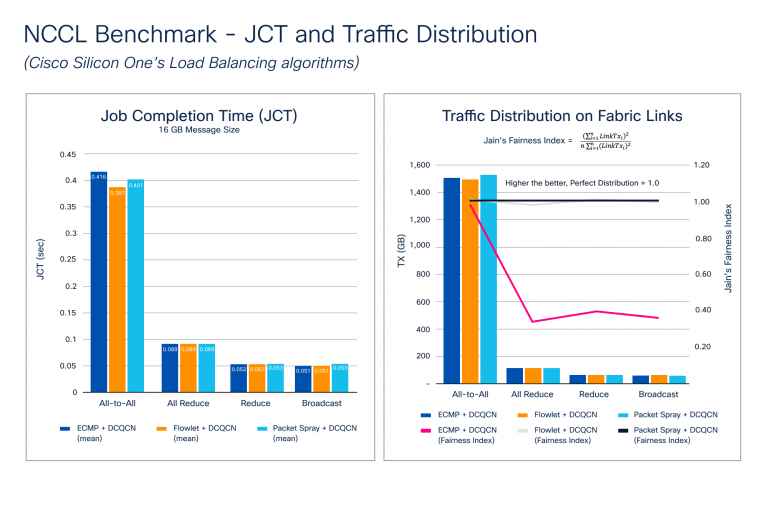
Figure 2 illustrates how the NCCL benchmarks stack up against different congestion avoidance features. We tested the most common collectives with multiple different message sizes to highlight these metrics. The results show that JCT improves with DLB and packet spray for All-to-All, which causes the most congestion due to the nature of communication. Although JCT is the most understood metric from an application’s perspective, JCT doesn’t show how effectively the network is utilized—something the infrastructure team needs to know. This knowledge could help them to:
- Improve the network utilization to get better JCT
- Know how many workloads can share the network fabric without adversely impacting JCT
- Plan for capacity as use cases increase
To gauge network fabric utilization, we calculated Jain’s Fairness Index, where LinkTxᵢ is the amount of transmitted traffic on fabric link:

The index value ranges from 0.0 to 1.0, with higher values being better. A value of 1.0 represents the perfect distribution. The Traffic Distribution on Fabric Links chart in Figure 2 shows how DLB and packet spray algorithms create a near-perfect Jain’s Fairness Index, so traffic distribution across the network fabric is almost perfect. ECMP uses static hashing, and depending on flow entropy, it can lead to traffic polarization, causing micro-congestion and negatively affecting JCT.
Silicon One versus NVIDIA Spectrum-X and InfiniBand
The NCCL Benchmark – Competitive Analysis (Figure 3) shows how Cisco Silicon One performs against NVIDIA Spectrum-X and InfiniBand technologies. The data for NVIDIA was taken from the SemiAnalysis publication. Note that Cisco does not know how these tests were performed, but we do know that the cluster size and GPU to network fabric connectivity is similar to the Cisco Zeus Cluster.
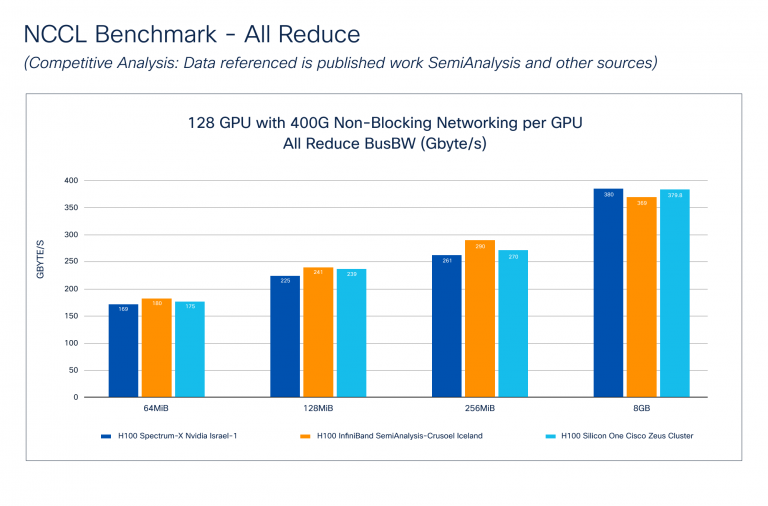
Bus Bandwidth (Bus BW) benchmarks the performance of collective communication by measuring the speed of operations involving multiple GPUs. Each collective has a specific mathematical equation reported during benchmarking. Figure 3 shows that Cisco Silicon One – All Reduce performs comparably to NVIDIA Spectrum-X and InfiniBand across various message sizes.
Network fabric performance assessment
The IBPerf Benchmark compares RDMA performance against ECMP, DLB, and packet spray, which are crucial for assessing network fabric performance. Incast scenarios, where multiple GPUs send data to one GPU, often cause congestion. We simulated these conditions using IBPerf tools.
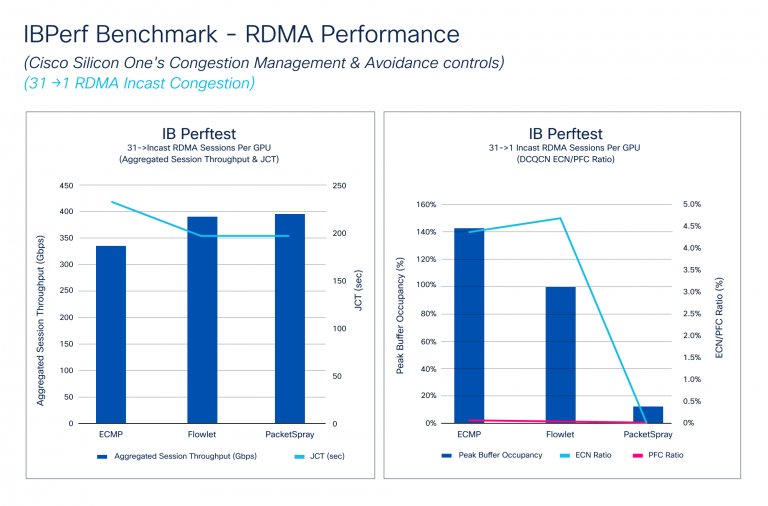
Figure 4 shows how Aggregated Session Throughput and JCT respond to different congestion avoidance algorithms: ECMP, DLB, and packet spray. DLB and packet spray reach Link Bandwidth, improving JCT. It also illustrates how DCQCN handles micro-congestions, with PFC and ECN ratios improving with DLB and significantly dropping with packet spray. Although JCT improves slightly from DLB to packet spray, the ECN ratio drops dramatically due to packet spray’s ideal traffic distribution.
Training and inference benchmark
The MLPerf Benchmark – Training and Inference, published by the MLCommons organization, aims to enable fair comparison of AI/ML systems and solutions.
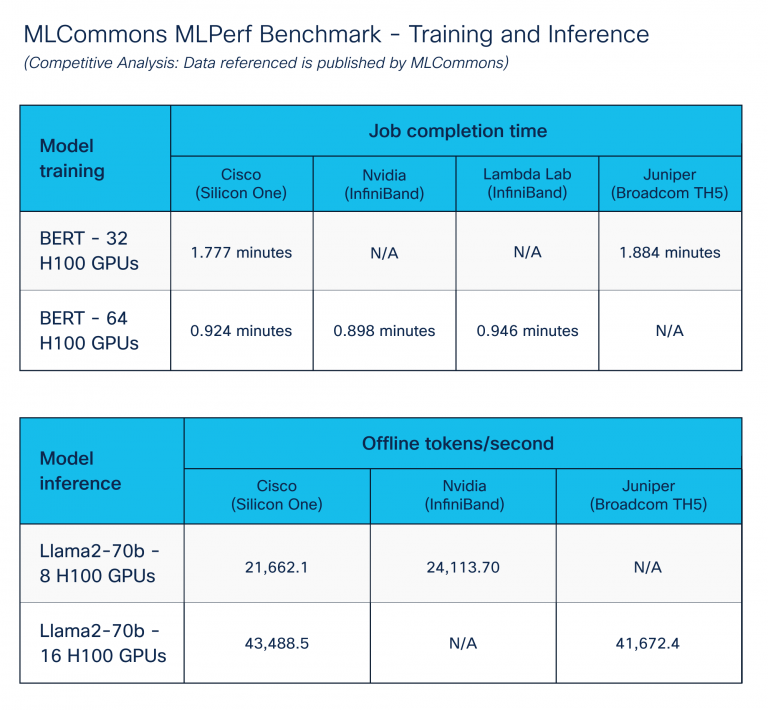
We focused on AI/ML data center solutions by executing training and inference benchmarks. To achieve optimal results, we extensively tuned across compute, storage, and networking components using congestion management features of Cisco Silicon One. Figure 5 shows comparable performance across various platform vendors. Cisco Silicon One with Ethernet performs like other vendor solutions for Ethernet.
Conclusion
Our deep dive into Ethernet and InfiniBand within AI/ML environments highlights the remarkable prowess of Cisco Silicon One in tackling congestion and boosting performance. These innovative advancements showcase the unwavering dedication of Cisco to provide robust, high-performance networking solutions that meet the rigorous demands of today’s AI/ML applications.
Many thanks to Vijay Tapaskar, Will Eatherton, and Kevin Wollenweber for their support in this benchmarking process.
Explore secure AI infrastructure
Discover secure, scalable, and high-performance AI infrastructure you need to develop, deploy, and manage AI workloads securely when you choose Cisco Secure AI Factory with NVIDIA.
Share:

{kind=link}