- I tested a Pixel Tablet without any Google apps, and it's more private than even my iPad
- My search for the best MacBook docking station is over. This one can power it all
- This $500 Motorola proves you don't need to spend more on flagship phones
- Finally, budget wireless earbuds that I wouldn't mind putting my AirPods away for
- I replaced my Linux system with this $200 Windows mini PC - and it left me impressed

Cisco Nexus 9000 Intelligent Buffers in a VXLAN/EVPN Fabric

As customers migrate to network fabrics based on Virtual Extensible Local Area Network/Ethernet Virtual Private Network (VXLAN/EVPN) technology, questions about the implications for application performance, Quality of Service (QoS) mechanisms, and congestion avoidance often arise. This blog post addresses some of the common areas of confusion and concern, and touches on a few best practices for maximizing the value of using Cisco Nexus 9000 switches for Data Center fabric deployments by leveraging the available Intelligent Buffering capabilities.
What Is the Intelligent Buffering Capability in Nexus 9000?
Cisco Nexus 9000 series switches implement an egress-buffered shared-memory architecture, as shown in Figure 1. Each physical interface has 8 user-configurable output queues that contend for shared buffer capacity when congestion occurs. A buffer admission algorithm called Dynamic Buffer Protection (DBP), enabled by default, ensures fair access to the available buffer among any congested queues.
In addition to DBP, two key features – Approximate Fair Drop (AFD) and Dynamic Packet Prioritization (DPP) – help to speed initial flow establishment, reduce flow-completion time, avoid congestion buildup, and maintain buffer headroom for absorbing microbursts.
AFD uses in-built hardware capabilities to separate individual 5-tuple flows into two categories – elephant flows and mouse flows:
- Elephant flows are longer-lived, sustained bandwidth flows that can benefit from congestion control signals such as Explicit Congestion Notification (ECN) Congestion Experienced (CE) marking, or random discards, that influence the windowing behavior of Transmission Control Protocol (TCP) stacks. The TCP windowing mechanism controls the transmission rate of TCP sessions, backing off the transmission rate when ECN CE markings, or un-acknowledged sequence numbers, are observed (see the “More Information” section for additional details).
- Mouse flows are shorter-lived flows that are unlikely to benefit from TCP congestion control mechanisms. These flows consist of the initial TCP 3-way handshake that establishes the session, along with a relatively small number of additional packets, and are subsequently terminated. By the time any congestion control is signaled for the flow, the flow is already complete.
As shown in Figure 2, with AFD, elephant flows are further characterized according to their relative bandwidth utilization – a high-bandwidth elephant flow has a higher probability of experiencing ECN CE marking, or discards, than a lower-bandwidth elephant flow. A mouse flow has a zero probability of being marked or discarded by AFD.
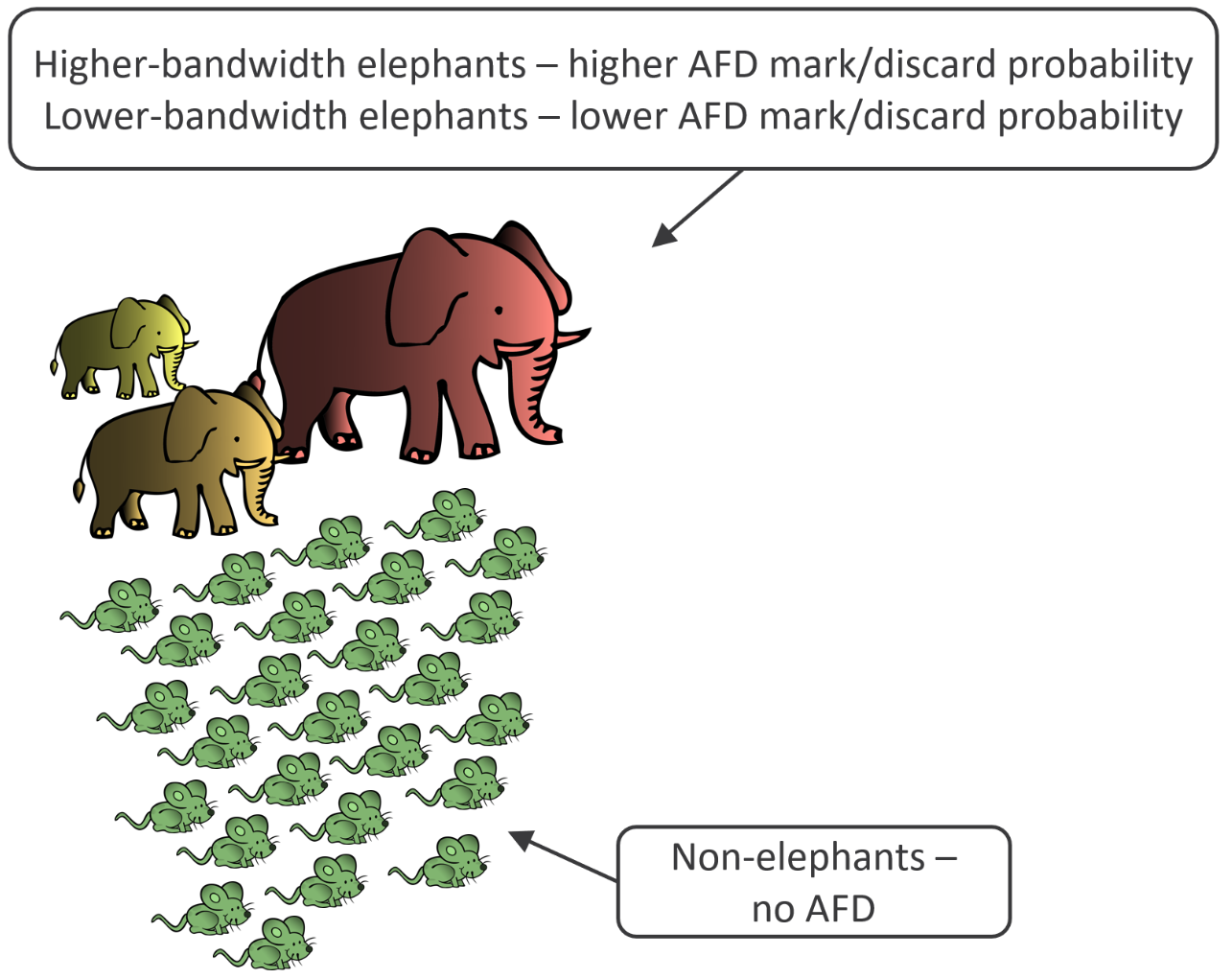
For readers familiar with the older Weighted Random Early Detect (WRED) mechanism, you can think of AFD as a kind of “bandwidth-aware WRED.” With WRED, any packet (regardless of whether it’s part of a mouse flow or an elephant flow) is potentially subject to marking or discards. In contrast, with AFD, only packets belonging to sustained-bandwidth elephant flows may be marked or discarded – with higher-bandwidth elephants more likely to be impacted than lower-bandwidth elephants – while a mouse flow is never impacted by these mechanisms.
Additionally, AFD marking or discard probability for elephants increases as the queue becomes more congested. This behavior ensures that TCP stacks back off well before all the available buffer is consumed, avoiding further congestion and ensuring that abundant buffer headroom still remains to absorb instantaneous bursts of back-to-back packets on previously uncongested queues.
DPP, another hardware-based capability, promotes the initial packets in a newly observed flow to a higher priority queue than it would have traversed “naturally.” Take for example a new TCP session establishment, consisting of the TCP 3-way handshake. If any of these packets sit in a congested queue, and therefore experience additional delay, it can materially affect application performance.
As shown in Figure 3, instead of enqueuing those packets in their originally assigned queue, where congestion is potentially more likely, DPP will promote those initial packets to a higher-priority queue – a strict priority (SP) queue, or simply a higher-weighted Deficit Weighted Round-Robin (DWRR) queue – which results in expedited packet delivery with a very low chance of congestion.
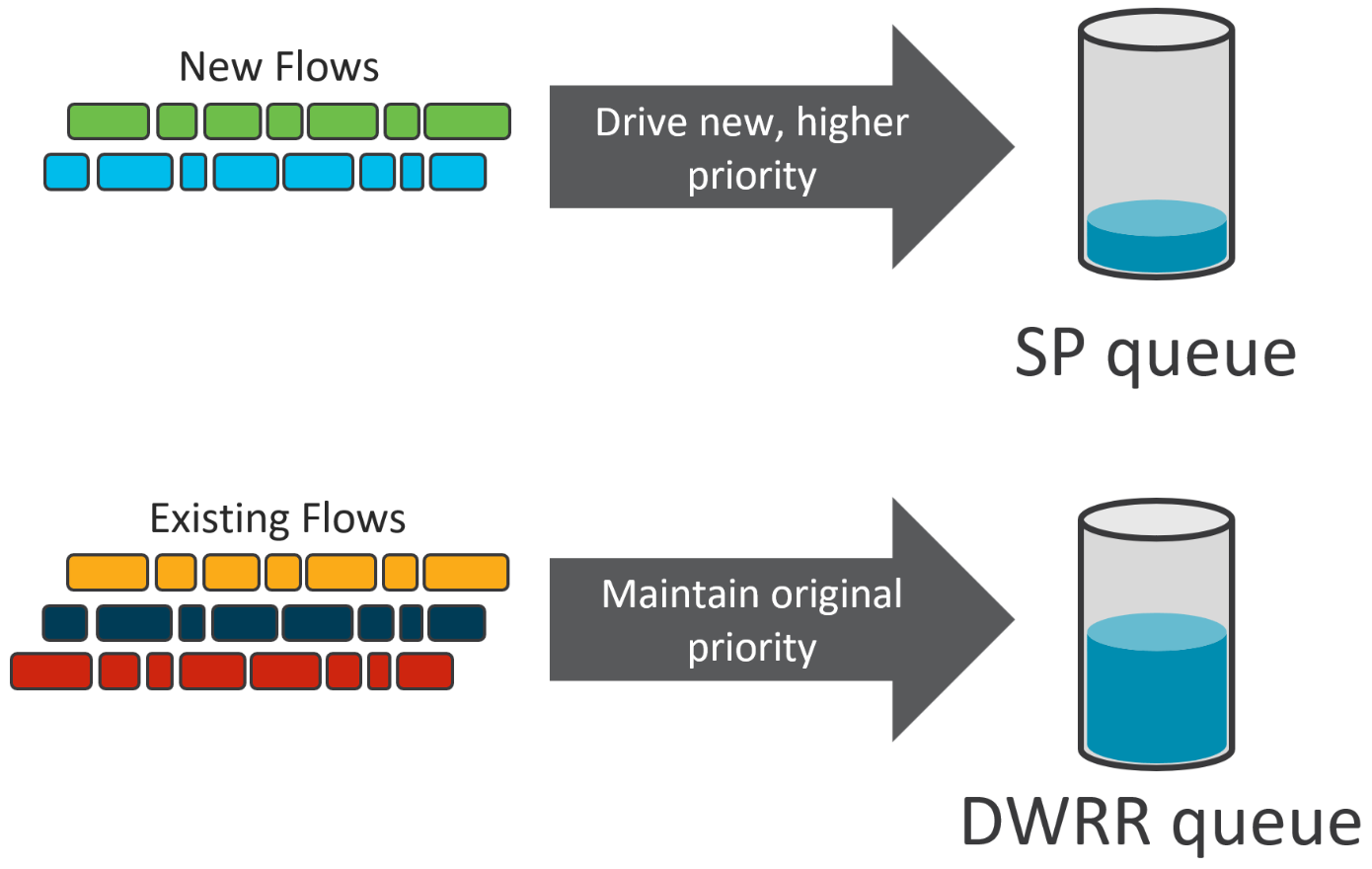
If the flow continues beyond a configurable number of packets, packets are no longer promoted – subsequent packets in the flow traverse the originally assigned queue. Meanwhile, other newly observed flows would be promoted and enjoy the benefit of faster session establishment and flow completion for short-lived flows.
AFD and UDP Traffic
One frequently asked question about AFD is if it’s appropriate to use it with User Datagram Protocol (UDP) traffic. AFD by itself does not distinguish between different protocol types, it only determines if a given 5-tuple flow is an elephant or not. We generally state that AFD should not be enabled on queues that carry non-TCP traffic. That’s an oversimplification, of course – for example, a low-bandwidth UDP application would never be subject to AFD marking or discards because it would never be flagged as an elephant flow in the first place.
Recall that AFD can either mark traffic with ECN, or it can discard traffic. With ECN marking, collateral damage to a UDP-enabled application is unlikely. If ECN CE is marked, either the application is ECN-aware and would adjust its transmission rate, or it would ignore the marking completely. That said, AFD with ECN marking won’t help much with congestion avoidance if the UDP-based application is not ECN-aware.
On the other hand, if you configure AFD in discard mode, sustained-bandwidth UDP applications may suffer performance issues. UDP doesn’t have any inbuilt congestion-management mechanisms – discarded packets would simply never be delivered and would not be retransmitted, at least not based on any UDP mechanism. Because AFD is configurable on a per-queue basis, it’s better in this case to simply classify traffic by protocol, and ensure that traffic from high-bandwidth UDP-based applications always uses a non-AFD-enabled queue.
What Is a VXLAN/EVPN Fabric?
VXLAN/EVPN is one of the fastest growing Data Center fabric technologies in recent memory. VXLAN/EVPN consists of two key elements: the data-plane encapsulation, VXLAN; and the control-plane protocol, EVPN.
You can find abundant details and discussions of these technologies on cisco.com, as well as from many other sources. While an in-depth discussion is outside the scope of this blog post, when talking about QOS and congestion management in the context of a VXLAN/EVPN fabric, the data-plane encapsulation is the focus. Figure 4 illustratates the VXLAN data-plane encapsulation, with emphasis on the inner and outer DSCP/ECN fields.
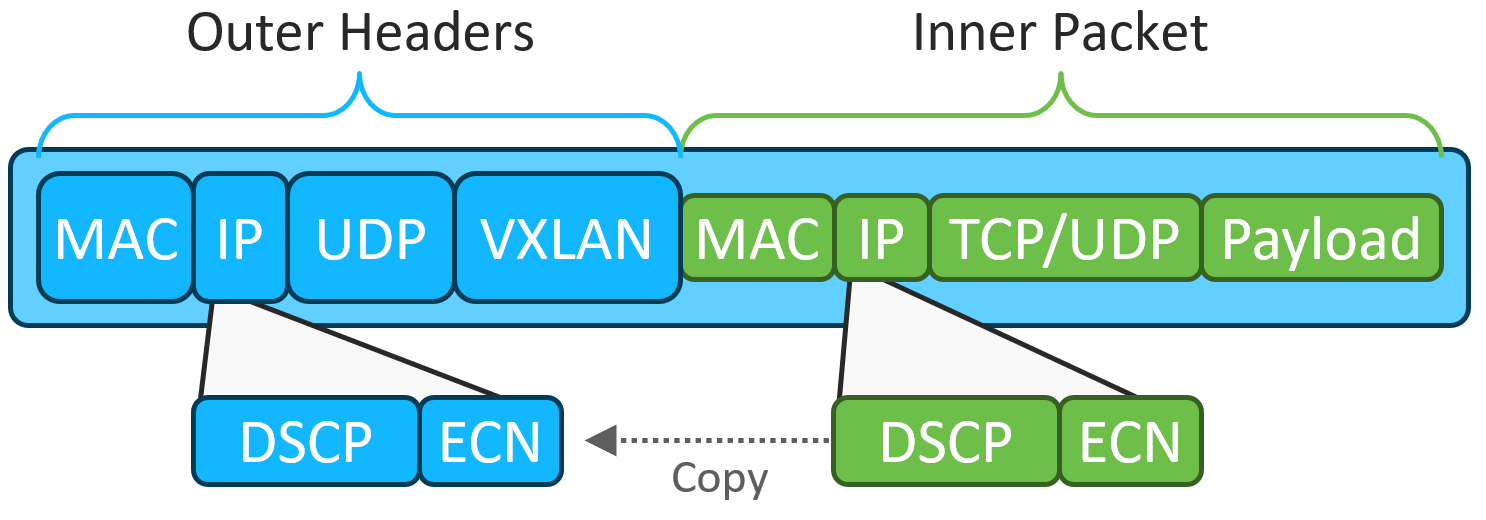
As you can see, VXLAN encapsulates overlay packets in IP/UDP/VXLAN “outer” headers. Both the inner and outer headers contain the DSCP and ECN fields.
With VXLAN, a Cisco Nexus 9000 switch serving as an ingress VXLAN tunnel endpoint (VTEP) takes a packet originated by an overlay workload, encapsulates it in VXLAN, and forwards it into the fabric. In the process, the switch copies the inner packet’s DSCP and ECN values to the outer headers when performing encapsulation.
Transit devices such as fabric spines forward the packet based on the outer headers to reach the egress VTEP, which decapsulates the packet and transmits it unencapsulated to the final destination. By default, both the DSCP and ECN fields are copied from the outer IP header into the inner (now decapsulated) IP header.
In the process of traversing the fabric, overlay traffic may pass through multiple switches, each enforcing QOS and queuing policies defined by the network administrator. These policies might simply be default configurations, or they may consist of more complex policies such as classifying different applications or traffic types, assigning them to unique classes, and controlling the scheduling and congestion management behavior for each class.
How Do the Intelligent Buffer Capabilities Work in a VXLAN Fabric?
Given that the VXLAN data-plane is an encapsulation, packets traversing fabric switches consist of the original TCP, UDP, or other protocol packet inside a IP/UDP/VXLAN wrapper. Which leads to the question: how do the Intelligent Buffer mechanisms behave with such traffic?
As discussed earlier, sustained-bandwidth UDP applications could potentially suffer from performance issues if traversing an AFD-enabled queue. However, we should make a very key distinction here – VXLAN is not a “native” UDP application, but rather a UDP-based tunnel encapsulation. While there is no congestion awareness at the tunnel level, the original tunneled packets can carry any kind of application traffic –TCP, UDP, or virtually any other protocol.
Thus, for a TCP-based overlay application, if AFD either marks or discards a VXLAN-encapsulated packet, the original TCP stack still receives ECN marked packets or misses a TCP sequence number, and these mechanisms will cause TCP to reduce the transmission rate. In other words, the original goal is still achieved – congestion is avoided by causing the applications to reduce their rate.
Similarly, high-bandwidth UDP-based overlay applications would respond just as they would to AFD marking or discards in a non-VXLAN environment. If you have high-bandwidth UDP-based applications, we recommend classifying based on protocol and ensuring those applications get assigned to non-AFD-enabled queues.
As for DPP, while TCP-based overlay applications will benefit most, especially for initial flow-setup, UDP-based overlay applications can benefit as well. With DPP, both TCP and UDP short-lived flows are promoted to a higher priority queue, speeding flow-completion time. Therefore, enabling DPP on any queue, even those carrying UDP traffic, should provide a positive impact.
Key Takeaways
VXLAN/EVPN fabric designs have gained significant traction in recent years, and ensuring excellent application performance is paramount. Cisco Nexus 9000 Series switches, with their hardware-based Intelligent Buffering capabilities, ensure that even in an overlay application environment, you can maximize the efficient utilization of available buffer, minimize network congestion, speed flow-establishment and flow-completion times, and avoid drops due to microbursts.
More Information
You can find more information about the technologies discussed in this blog at www.cisco.com:
Share:
