- I tested a Pixel Tablet without any Google apps, and it's more private than even my iPad
- My search for the best MacBook docking station is over. This one can power it all
- This $500 Motorola proves you don't need to spend more on flagship phones
- Finally, budget wireless earbuds that I wouldn't mind putting my AirPods away for
- I replaced my Linux system with this $200 Windows mini PC - and it left me impressed

How to Get Started with the Weaviate Vector Database on Docker | Docker

Vector databases have been getting a lot of attention since the developer community realized how they can enhance large language models (LLMs). Weaviate is an open source vector database that enables modern search capabilities, such as vector search, hybrid search, and generative search. With Weaviate, you can build advanced LLM applications, next-level search systems, recommendation systems, and more.
This article explains what vector databases are and highlights key features of the Weaviate vector database. Learn how to install Weaviate on Docker using Docker Compose so you can take advantage of semantic search within your Dockerized environment.

Introducing the Weaviate vector database
The core feature of vector databases is storing vector embeddings of data objects. This functionality is especially helpful with the growing amount of unstructured data (e.g., text or images), which is difficult to manage and process with traditional relational databases. The vector embeddings are a numerical representation of the data objects — usually generated by a machine learning (ML) model — and enable the search and retrieval of data based on semantic similarity (vector search).
Vector databases do much more than just store vector embeddings: As you can imagine, retrieving data based on similarity requires a lot of comparing between objects and thus can take a long time. In contrast to other types of databases that can store vector embeddings, a vector database can retrieve data fast. To enable low-latency search queries, vector databases use specific algorithms to index the data.
Additionally, some vector databases, like Weaviate, store the vector embeddings and the original data object, which lets you combine traditional search with modern vector search for more accurate search results.
With these functionalities, vector databases are usually used in search or similar tasks (e.g., recommender systems). With the recent advancements in the LLM space, however, vector databases have also proven effective at providing long-term memory and domain-specific context to conversational LLMs. This means that you can leverage LLM capabilities on your private data or your specific field of expertise.
Key highlights of the Weaviate vector database include:
- Open source: Weaviate is open source and available for anybody to use wherever they want. It is also available as a managed service with SaaS and hybrid SaaS options.
- Horizontal scalability: You can scale seamlessly into billions of data objects for your exact needs, such as maximum ingestion, largest possible dataset size, maximum queries per second, etc.
- Lightning-fast vector search: You can perform lightning-fast pure vector similarity search over raw vectors or data objects, even with filters. Weaviate typically performs nearest-neighbor searches of millions of objects in considerably less than 100ms (see our benchmark).
- Combined keyword and vector search (hybrid search): You can store both data objects and vector embeddings. This approach allows you to combine keyword-based and vector searches for state-of-the-art search results.
- Optimized for cloud-native environments: Weaviate has the fault tolerance of a cloud-native database, and the core Docker image is comparably small at 18 MB.
- Modular ecosystem for seamless integrations: You can use Weaviate standalone (aka “bring your own vectors”) or with various optional modules that integrate directly with OpenAI, Cohere, Hugging Face, etc., to enable easy use of state-of-the-art ML models. These modules can be used as vectorizers to automatically vectorize any media type (text, images, etc.) or as generative modules to extend Weaviate’s core capabilities (e.g., question answering, generative search, etc.).
Prerequisites
Ensure you have both the docker and the docker-compose CLI tools installed. For the following section, we assume you have Docker 17.09.0 or higher and Docker Compose V2 installed. If your system has Docker Compose V1 installed instead of V2, use docker-compose instead of docker compose. You can check your Docker Compose version with:
How to Configure the Docker Compose File for Weaviate
To start Weaviate with Docker Compose, you need a Docker Compose configuration file, typically called docker-compose.yml. Usually, there’s no need to obtain individual images, as we distribute entire Docker Compose files.
You can obtain a Docker Compose file for Weaviate in two different ways:
- Docker Compose configurator on the Weaviate website (recommended): The configurator allows you to customize your
docker-compose.ymlfile for your purposes (including all module containers) and directly download it. - Manually: Alternatively, if you don’t want to use the configurator, copy and paste one of the example files from the documentation and manually modify it.
This article will review the steps to configure your Docker Compose file with the Weaviate Docker Compose configurator.
Step 1: Version
First, define which version of Weaviate you want to use (Figure 1). We recommend always using the latest version.
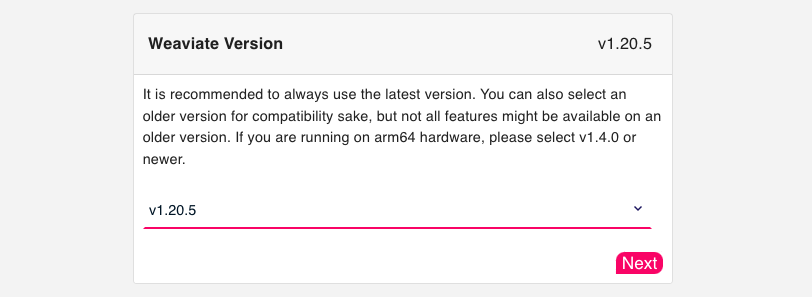
The following shows a minimal example of a Docker Compose setup for Weaviate:
version: '3.4'
services:
weaviate:
image: semitechnologies/weaviate:1.20.5
ports:
- 8080:8080
restart: on-failure:0
environment:
QUERY_DEFAULTS_LIMIT: 25
AUTHENTICATION_ANONYMOUS_ACCESS_ENABLED: 'true'
PERSISTENCE_DATA_PATH: '/var/lib/weaviate'
DEFAULT_VECTORIZER_MODULE: 'none'
CLUSTER_HOSTNAME: 'node1'
Step 2: Persistent volume
Configure persistent volume for Docker Compose file (Figure 2):
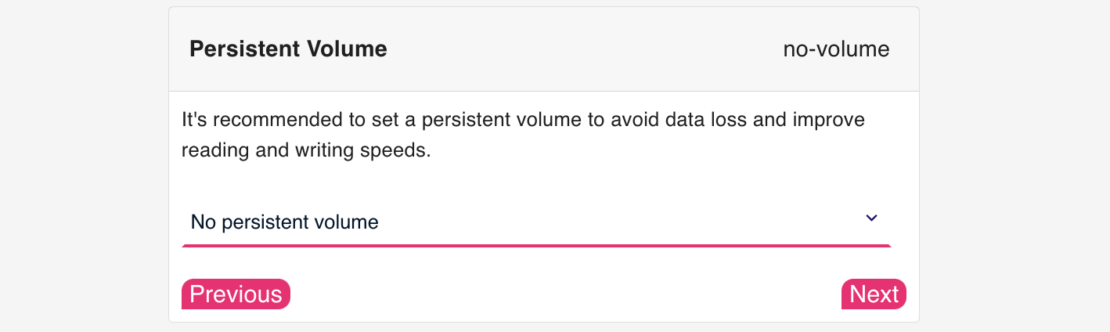
Setting up a persistent volume to avoid data loss when you restart the container and improve reading and writing speeds is recommended.
You can set a persistent volume in two ways:
- With a named volume: Docker will create a named volume
weaviate_dataand mount it to thePERSISTENCE_DATA_PATHinside the container after starting Weaviate with Docker Compose:
services:
weaviate:
volumes:
- weaviate_data:/var/lib/weaviate
# etc.
volumes:
weaviate_data:
- With host binding: Docker will mount
./weaviate_dataon the host to thePERSISTENCE_DATA_PATHinside the container after starting Weaviate with Docker Compose:
services:
weaviate:
volumes:
- ./weaviate_data:/var/lib/weaviate
# etc.
Step 3: Modules
Weaviate can be used with various modules, which integrate directly with inferencing services like OpenAI, Cohere, or Hugging Face. These modules can be used to vectorize any media type at import and search time automatically or to extend Weaviate’s core capabilities with generative modules.
You can also use Weaviate without any modules (standalone). In this case, no model inference is performed at import or search time, meaning you need to provide your own vectors in both scenarios. If you don’t need any modules, you can skip to Step 4: Runtime.
Configure modules for Docker Compose file (Figure 3):
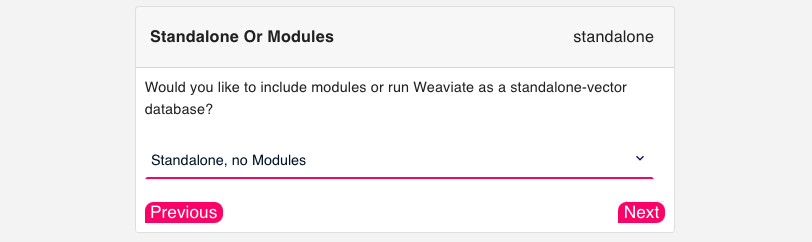
Currently, Weaviate integrates three categories of modules:
- Retriever and vectorizer modules automatically vectorize any media type (text, images, etc.) at import and search time. There are also re-ranker modules available for re-ranking search results.
- Reader and generator modules can be used to extend Weaviate’s core capabilities after retrieving the data for generative search, question answering, named entity recognition (NER), and summarization.
- Other modules are available for spell checking or for enabling using your custom modules.
Note that many modules (e.g., transformer models) are neural networks built to run on GPUs. Although you can run them on CPU, enabling GPU `ENABLE_CUDA=1`, if available, will result in faster inference.
The following shows an example of a Docker Compose setup for Weaviate with the sentence-transformers model:
version: '3.4'
services:
weaviate:
image: semitechnologies/weaviate:1.20.5
restart: on-failure:0
ports:
- "8080:8080"
environment:
QUERY_DEFAULTS_LIMIT: 20
AUTHENTICATION_ANONYMOUS_ACCESS_ENABLED: 'true'
PERSISTENCE_DATA_PATH: "./data"
DEFAULT_VECTORIZER_MODULE: text2vec-transformers
ENABLE_MODULES: text2vec-transformers
TRANSFORMERS_INFERENCE_API: http://t2v-transformers:8080
CLUSTER_HOSTNAME: 'node1'
t2v-transformers:
image: semitechnologies/transformers-inference:sentence-transformers-multi-qa-MiniLM-L6-cos-v1
environment:
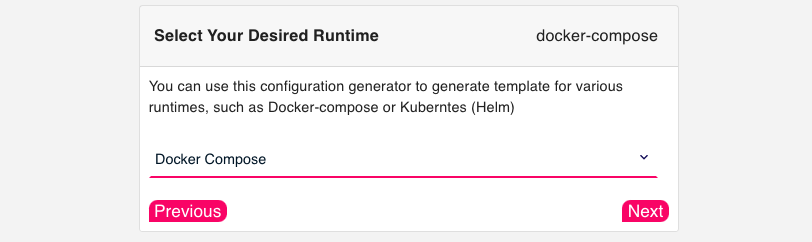
Step 4: Runtime
In the final step of the configurator, select Docker Compose for your runtime (Figure 4):
Step 5: Download and further customization
Once your configuration is complete, you will see a snippet similar to the following to download the docker-compose.yml file, which has been adjusted to your selected configuration.
$ curl -o docker-compose.yml "https://configuration.weaviate.io/v2/docker-compose/docker-compose.yml?<YOUR-CONFIGURATION>"
After downloading the Docker Compose file from the configurator, you can directly start Weaviate on Docker or customize it further.
You can set additional environment variables to further customize your Weaviate setup (e.g., by defining authentication and authorization). Additionally, you can create a multi-node setup with Weaviate by defining a founding member and other members in the cluster.
Founding member: Set up one node as a “founding” member by configuring CLUSTER_GOSSIP_BIND_PORT and CLUSTER_DATA_BIND_PORT:
weaviate-node-1: # Founding member service name
... # truncated for brevity
environment:
CLUSTER_HOSTNAME: 'node1'
CLUSTER_GOSSIP_BIND_PORT: '7100'
CLUSTER_DATA_BIND_PORT: '7101'
Other members in the cluster: For each further node, configure CLUSTER_GOSSIP_BIND_PORT and CLUSTER_DATA_BIND_PORT and configure to join the founding member’s cluster using the CLUSTER_JOIN variable:
weaviate-node-2:
... # truncated for brevity
environment:
CLUSTER_HOSTNAME: 'node2'
CLUSTER_GOSSIP_BIND_PORT: '7102'
CLUSTER_DATA_BIND_PORT: '7103'
CLUSTER_JOIN: 'weaviate-node-1:7100' # This must be the service name of the "founding" member node.
Optionally, you can set a hostname for each node using CLUSTER_HOSTNAME.
Note that it’s a Weaviate convention to set the CLUSTER_DATA_BIND_PORT to 1 higher than CLUSTER_GOSSIP_BIND_PORT.
How to run Weaviate on Docker
Once you have your Docker Compose file configured to your needs, you can run Weaviate in your Docker environment.
Start Weaviate
Before starting Weaviate on Docker, ensure that the Docker Compose file is named exactly docker-compose.yml and that you are in the same folder as the Docker Compose file.
Then, you can start up with the whole setup by running:
The -d option runs containers in detached mode. This means that your terminal will not attach to the log outputs of all the containers.
If you want to attach to the logs of specific containers (e.g., Weaviate), you can run the following command:
$ docker compose up -d && docker compose logs -f weaviate
Congratulations! Weaviate is now running and is ready to be used.
Stop Weaviate
To avoid losing your data, shut down Weaviate with the following command:
This will write all the files from memory to disk.
Conclusion
This article introduced vector databases and how they can enhance LLM applications. Specifically, we highlighted the open source vector database Weaviate, whose advantages include fast vector search at scale, hybrid search, and integration modules to state-of-the-art ML models from OpenAI, Cohere, Hugging Face, etc.
We also provided a step-by-step guide on how to install Weaviate on Docker using Docker Compose, noting that you can obtain a docker-compose.yml file from the Weaviate Docker Compose configurator, which helps you to customize your Docker Compose file for your specific needs.
Learn more about how developers are using Docker to accelerate the development of their AI/ML applications by looking at the AI/ML section on Docker.com.
