- Why I recommend this OnePlus phone over the S25 Ultra - especially at this new low price
- I replaced my laptop with Microsoft's 12-inch Surface Pro for weeks - here's my buying advice now
- This palm recognition smart lock doubles as a video doorbell (and has no monthly fees)
- Samsung is giving these Galaxy phones a big One UI upgrade - here's which models qualify
- 7 MagSafe accessories that I recommend every iPhone user should have

Building Data Center Infrastructure for the AI Revolution

This is part two of a multi-part blog series on AI. Part one, Why 2024 is the Year of AI for Networking, discussed Cisco’s AI networking vision and strategy. This blog will focus on evolving data center network infrastructure for supporting AI/ML workloads, while the next blog will discuss the Cisco compute strategy and innovations for mainstreaming AI.
As discussed in part one of the blog series, Artificial intelligence (AI) and machine learning (ML) have recently experienced a steep investment trajectory recently, catapulted by generative AI. This has opened up new opportunities to deliver actionable insights and real-world problem-solving capabilities.
Generative AI requires a significant amount of processing power and higher networking performance to deliver outcomes rapidly. Hyperscalers have led the AI revolution with mass-scale infrastructure using thousands of graphics processing units (GPUs) to process petabytes of data for AI workloads, such as training models. Many organizations, including enterprise, public sector, service providers, and Tier 2 web-scalers, are exploring or starting to use generative AI with training and inference models.
To process AI/ML workloads or jobs that involve large data sets, it is necessary to distribute them across multiple GPUs in an AI/ML cluster. This helps balance the load through parallel processing and deliver high-quality results quickly. To achieve this, it is essential to have a high-performance network that supports non-blocking, low-latency, lossless fabric. Without such a network, latency or packet drops can cause learning jobs to take much longer to complete, or may not complete at all. Similarly, when running AI inferencing in edge data centers, it is vital to have a robust network to deliver real-time insights to a large number of end-users.
Why Ethernet?
The foundation for most networks today is Ethernet, which has evolved from use in 10Mbps LANs to WANs with 400GbE ports. Ethernet’s adaptability has allowed it to scale and evolve to meet new demands, including those of AI. It has successfully overcome challenges such as scaling past DS1, DS3, and SONET speeds, while maintaining the quality of service for voice and video traffic. This adaptability and resilience have allowed Ethernet to outlast alternatives such as Token Ring, ATM, and frame relay.
To help improve throughput and lower compute and storage traffic latency, the remote direct memory access (RDMA) over Converged Ethernet (RoCE) network protocol is used to support remote access to memory on a remote host without CPU involvement. Ethernet fabrics with RoCEv2 protocol support are optimized for AI/ML clusters with widely adopted standards-based technology, easier migration for Ethernet-based data centers, proven scalability at lower cost-per-bit, and designed with advanced congestion management to help intelligently control latency and loss.
According to the Dell’oro Group, AI networks will act as a catalyst to accelerate the transition to higher speeds. Market demand from “Tier 2/3 and large enterprises are forecast to be significant, approaching $10 B over the next five years,” and they are expected to prefer Ethernet.
Why Cisco AI infrastructure?
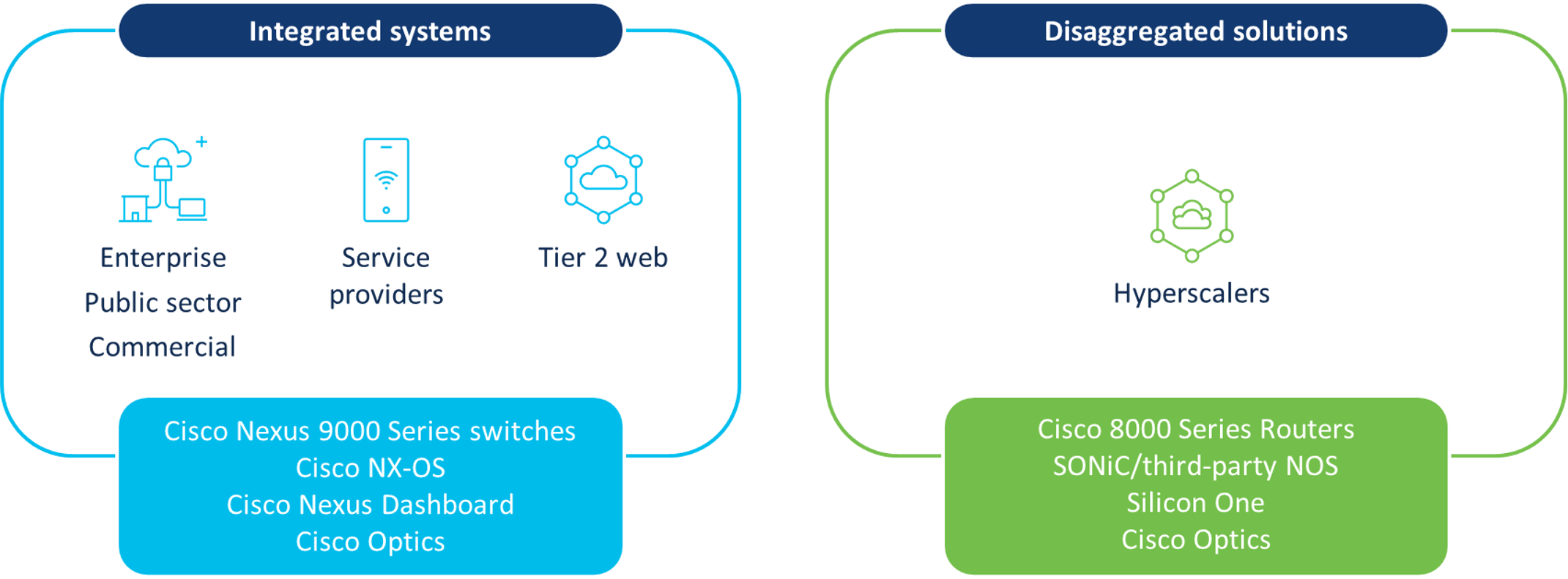
We have made significant investments in our data center networking portfolio for AI infrastructure across platforms, software, silicon, and optics. This include Cisco Nexus 9000 Series switches, Cisco 8000 Series Routers, Cisco Silicon One, network operating systems (NOSs), management, and Cisco Optics (see Figure 1).
Figure 1. Cisco AI/ML data center infrastructure solutions
This portfolio is designed for data center Ethernet networks transporting AI/ML workloads, such as running inference models on Cisco unified computing system (UCS) servers. Customers need choices, which is why we are providing flexibility with different options.
Cisco Nexus 9000 Series switches are integrated solutions that deliver high-throughput and provide congestion management to help reduce latency and traffic drops across AI/ML clusters. Cisco Nexus Dashboard helps view and analyze telemetry, and can help quickly configure AI/ML networks with automation, including congestion parameters, ports, and adding leaf/spine switches. This solution provides AI/ML ready networks for customers to meet the key requirements, with a blueprint for network infrastructure and operations.
Cisco 8000 Series Routers support disaggregation for data center use cases requiring high-capacity open platforms using Ethernet—such as AI/ML clusters in the hyperscaler segment. For these use cases, the NOS on the Cisco 8000 Series Routers can be third-party or Software for Open Networking in the Cloud (SONiC), which is community-supported and designed for customers needing an open-source solution. Cisco 8000 Series Routers also support IOS XR software for other data center routing use cases, including super-spine, data center interconnect, and WAN.
Our solutions portfolio leverages Cisco Silicon One, which is Cisco chip innovation based on a unified architecture that delivers high-performance with resource efficiency. Cisco Silicon One is optimized for latency control with AI/ML clusters using Ethernet, telemetry-assisted Ethernet, or fully scheduled fabric. Cisco Optics enable high throughput on Cisco routers and switches, scaling up to 800G per port to help meet the demands of AI infrastructure.
We are also helping customers with their budgetary and sustainability goals through hardware and software innovation. For example, system scalability and Cisco Silicon One power efficiency help reduce the amount of resources required for AI/ML interconnects. Customers can access network visibility into actual usage of power and carbon footprint such as KWh, cost, and CO2 emissions via Cisco Nexus Dashboard Insights.
With this AI/ML infrastructure solutions portfolio, Cisco is helping customers deliver high-quality experiences for their end-users with fast insights, through sustainable, high-performance AI/ML Ethernet fabrics that are intelligent and operationally efficient.
Is my data center ready to support AI/ML applications?
Data center architectures need to be designed properly to support AI/ML workloads. To help customers accomplish this goal, we applied our extensive data center networking experience to create a data center networking blueprint for AI/ML applications (see Figure 2), which discusses how to:
- Build automated, scalable, low-latency, Ethernet networks with support for lossless transport, using congestion management mechanisms such as explicit congestion notification (ECN) and priority flow control (PFC) to support RoCEv2 transport for GPU memory-to-memory transfer of information.
- Design a non-blocking network to further improve performance and enable faster completion rates of AI/ML jobs.
- Quickly automate configuration of the AI/ML network fabric, including congestion management parameters for quality-of-service (QoS) control.
- Achieve different levels of visibility into the network through telemetry to help quickly troubleshoot issues and improve transport performance, such as real-time congestion statistics that can help identify ways to tune the network.
- Leverage the Cisco Validated Design for Data Center Network Blueprint for AI/ML, which includes configuration examples as best practices on building AI/ML infrastructure.
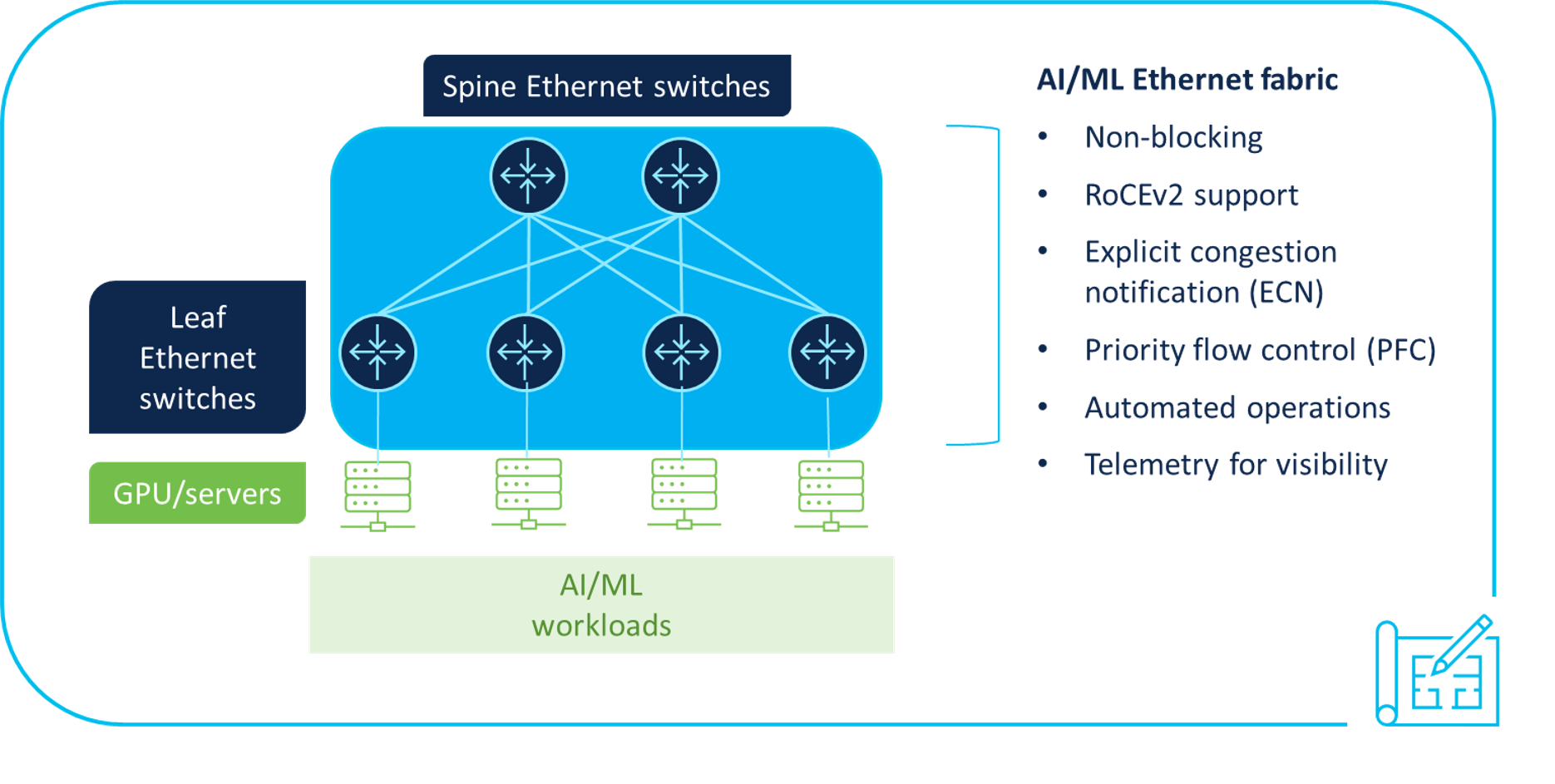
Figure 2. Cisco AI data center networking blueprint
How do I get started?
Evolving to a next-gen data center may not be straightforward for all customers, which is why Cisco is collaborating with NVIDIA® to deliver AI infrastructure solutions for the data center that are easy to deploy and manage by enterprises, public sector organizations, and service providers (see Figure 3).
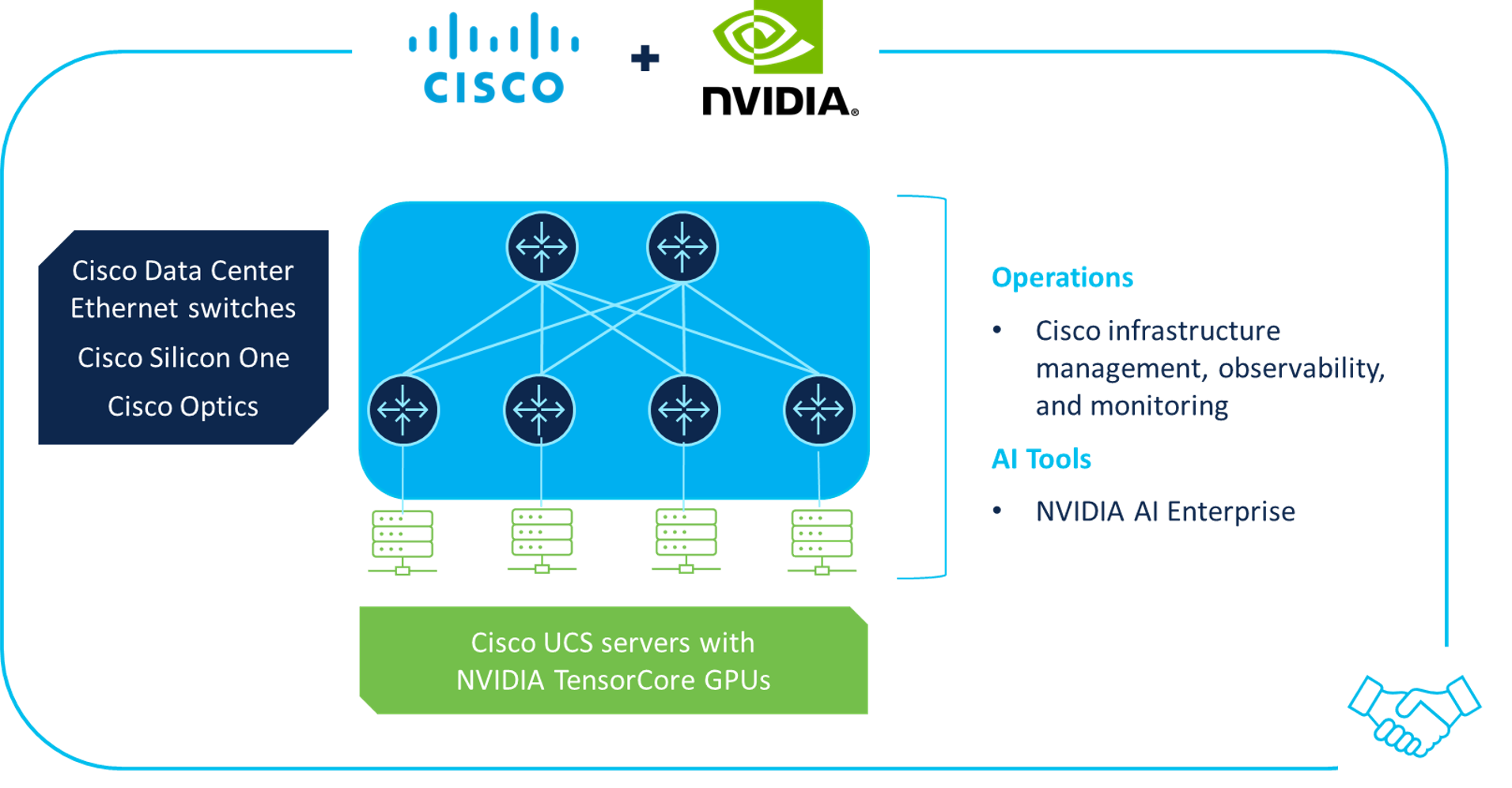
Figure 3. Cisco/NVIDIA partnership
By combining industry-leading technologies from Cisco and NVIDIA, integrated solutions include:
- Cisco data center Ethernet infrastructure: Cisco Nexus 9000 Series switches and Cisco 8000 Series Routers, including Cisco Optics and Cisco Silicon One, for high-performance AI/ML data center network fabrics that control latency and loss to enable better experiences with timely results for AI/ML workloads
- Cisco Compute: M7 generation of UCS rack and blade servers enable optimal compute performance across a broad array of AI and data-intensive workloads in the data center and at the edge
- Infrastructure management and operations: Cisco Networking Cloud with Cisco Nexus Dashboard and Cisco Intersight, digital experience monitoring with Cisco ThousandEyes, and cross-domain telemetry analytics with the Cisco Observability Platform
- NVIDIA Tensor Core GPUs: Latest-generation processors optimized for AI/ML workloads, used in UCS rack and blade servers
- NVIDIA BlueField-3 SuperNICs: Purpose-built network accelerators for modern AI workloads, providing high-performance network connectivity between GPU servers
- NVIDIA BlueField-3 data processing units (DPUs): Cloud infrastructure processors for offloading, accelerating, and isolating software-defined networking, storage, security, and management functions, significantly enhancing data center performance, efficiency, and security
- NVIDIA AI Enterprise: Software frameworks, pretrained models, and development tools, as well as new NVIDIA NIM microservices, for more secure, stable, and supported production AI
- Cisco Validated Designs: Validated reference architectures designed help to simplify deployment and management of AI clusters at any scale in a wide range of use cases spanning virtualized and containerized environments, with both converged and hyperconverged options
- Partners: Cisco’s global ecosystem of partners can help advise, support, and guide customers in evolving their data centers to support AI/ML applications
Leading the way
Cisco’s collaboration with NVIDIA goes beyond selling existing solutions through Cisco sellers/partners, as more technological integrations are planned. Through these innovations and working with NVIDIA, we are helping enterprise, public sector, service provider and web-scale customers on the data center journeys to fully enabled AI/ML infrastructures, including for training and inference models.
We’ll be at NVIDIA GTC, a global AI conference running March 18–21, so visit us at Booth #1535 to learn more.
In the next blog of this series, Jeremy Foster, SVP/GM, Cisco Compute, will focus on the Cisco Compute strategy and innovations for mainstreaming AI.
Find out more from the press release
Share:

{kind=link}