- Palo Alto Networks to buy Protect AI, strengthen AI security platform
- Brocade Fabric OS flaw could allow code injection attacks
- How an 'internet of agents' could help AIs connect and work together
- Tenable Appoints Eric Doerr as Chief Product Officer
- OIN marks 20 years of defending Linux and open source from patent trolls

Cisco Silicon One Breaks the 51.2 Tbps Barrier

In December 2019, we made a bold announcement about how we’d forever change the economics of the internet and drive innovation at speeds like no one had ever seen before. These were ambitious claims, and not surprisingly, many people took a wait-and-see attitude. Since then, we’ve continued to innovate at an increasingly fast pace, leading the industry with innovative solutions that meet our customers’ needs.
Today, just three and a half years after launching Cisco Silicon One™, we’re proud to announce our fourth-generation set of devices, the Cisco Silicon One G200 and Cisco Silicon One G202, which we are sampling to customers now. Typically, new generations are launched every 18 to 24 months, demonstrating a pace of innovation that’s two times faster than normal silicon development.
The Cisco Silicon One G200 offers the benefits of our unified architecture and focuses specifically on enhanced Ethernet-based artificial intelligence/machine learning (AI/ML) and web-scale spine deployments. The Cisco Silicon One G200 is a 5 nm, 51.2 Tbps, 512 x 112 Gbps serializer-deserializer (SerDes) device. It is a uniquely programmable, deterministic, low-latency device with advanced visibility and control, making it the ideal choice for web-scale networks.
The Cisco Silicon One G202 brings similar benefits to customers who still want to use the 50G SerDes for connecting optics to the switch. It is a 5 nm, 25.6 Tbps, 512 x 56 Gbps SerDes device with the same characteristics as the Cisco Silicon One G200 but with half the performance.
To achieve the vision of Cisco Silicon One, it was imperative for us to invest in key technologies. Seven years ago, Cisco began investing in our own high-speed SerDes development and realized immediately that as speeds increase, the industry must move to analog-to-digital (ADC)-based SerDes. SerDes acts as a fundamental building block of networking interconnect for high-performance compute and AI deployments. Today, we are pleased to announce our next-generation, ultra-high performance, and low-power 112 Gbps ADC SerDes capable of ultra-long reach channels supporting 4-meter direct-attach cables (DACs), traditional optics, linear drive optics (LDO), and co-packaged optics (CPO), while minimizing silicon die area and power.
The Cisco Silicon One G200 and G202 are uniquely positioned in the industry with advanced features to optimize real-world performance of AI/ML workloads—while simultaneously driving down the cost, power, and latency of the network with significant innovations.
The Cisco Silicon One G200 is the ideal solution for Ethernet-based AI/ML networks for several reasons:
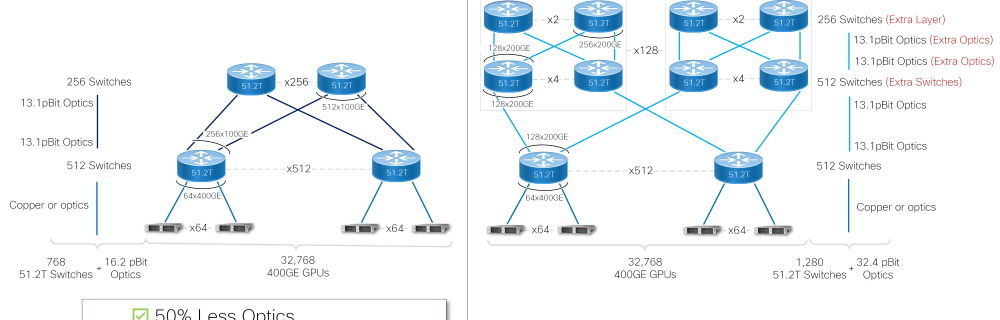
~ With the industry’s highest radix switch, with 512 x 100GE Ethernet ports on one device, customers can build a 32K 400G GPUs AI/ML cluster with a 2-layer network requiring 50% less optics, 40% fewer switches, and 33% fewer networking layers—drastically reducing the environmental footprint of the AI/ML cluster. This saves up to 9 million kWh per year, which according to the U.S. Environmental Protection Agency is equivalent to more than 6,000 metric tons of carbon dioxide (CO2e) or burning 7.3 million pounds of coal per year.
~ Advanced congestion-aware load balancing techniques enable networks to avoid traditional congestion events.
~ Advanced packet-spraying techniques minimize creation of congestion hot spots in the network.
~ Advanced hardware-based link-failure recovery delivers optimal performance across massive web-scale networks, even in the presence of faults.
Here’s a closer look at some of our many Cisco Silicon One–related innovations:
Converged architecture
~ Cisco Silicon One provides one architecture that can be deployed across customer networks, from routing roles to web-scale front-end networks to web-scale back-end networks, dramatically reducing deployment timelines, while simultaneously minimizing ongoing operations costs by enabling a converged infrastructure.
~ Using a common software development kit (SDK) and standard Switch Abstraction Interface (SAI) layers, customers need only port the Cisco Silicon One environment to their network operating system (NOS) once and make use of that investment across diverse network roles.
~ Like all our devices, the Cisco Silicon One G200 has a large and fully unified packet-buffer optimizing burst-absorption and throughput in large web-scale networks. This minimizes head-of-line blocking by absorbing bursts instead of the generation of priority flow control.
Optimization across the entire value chain
~ The Cisco Silicon One G200 has up to two times higher radix than other solutions with 512 Ethernet MACs, enabling customers to significantly reduce the cost, power, and latency of network deployments by removing layers of their network.
~ With our own internally developed, next-generation, SerDes technology, the Cisco Silicon One G200 device is capable of driving 43 dB bump-to-bump channels that enable co-packaged optics (CPO), linear pluggable objects (LPO), and the use of 4-meter 26 AWG copper cables, which is well beyond IEEE standards for optimal in-rack connectivity.
~ The Silicon One G200 is over two times more power efficient with two times lower latency compared to our already optimized Cisco Silicon One G100 device.
~ The physical design and layout of the device is built with a system-first approach, allowing customers to run system fans slower, dramatically decreasing system power draw.
Innovative load balancing and fault detection
~ Support for non-correlated, weighted equal-cost multipath (WECMP) and equal-cost multipath (ECMP) load balancing capabilities with near-ideal characteristics help to avoid hash polarization, even across massive networks.
~ Congestion-aware load balancing for stateful ECMP, flow, and flowlet enables optimal network throughput with optimal flow-completion time and job-completion time (JCT).
~ Congestion-aware stateless packet spraying enables near ideal JCT by using all available network bandwidth, regardless of flow characteristics.
~ Support for hardware-based redistribution of packets based on link failures enables Cisco Silicon One G200 to optimize real-world throughput of massive scale networks.
Advanced packet processor
~ The Cisco Silicon One G200 uses the industry’s first fully custom, P4 programmable parallel packet processor capable of launching more than 435 billion lookups per second. It supports advanced features like SRv6 Micro-SID (uSID) at full rate and is extendable with full run-to-completion processing for even more complex flows. This unique packet processing architecture enables flexibility with deterministic low latency and power.
Deep visibility and analytics
~ Programmable processors enable support for standard and emerging web-scale in-band telemetry standards providing industry-leading network visibility.
~ Embedded hardware analyzers detect microbursts with pre- and post-event logging of temporal flow information, giving network operators the ability to analyze network events after the fact with hardware time visibility.
A new generation of network capabilities
Gone are the days when the industry operated in silos. With its one unified architecture, Cisco Silicon One erases the hard dividing lines that have defined our industry for too long. Customers no longer need to worry about architectural differences rooted in past imagination and technology limitations. Today, customers can deploy Cisco Silicon One in a multitude of ways across their networks.
With the Cisco Silicon One G200 and G202 devices, we extend the reach of Cisco Silicon One with optimized high-bandwidth devices purpose-built for spine and AI/ML deployments. Customers can save money by deploying fewer and more efficient devices, enjoy new deployment topologies with ultra-long-reach SerDes, improve their AI/ML job performance with innovative load balancing and fault discovery techniques, and improve network debuggability with advanced telemetry and hardware analyzers.
If you’ve been watching since we first announced Cisco Silicon One in December 2019, it is easy to see that this is just the beginning. We’re looking forward to continuing to accelerate the value addition for our customers.
Stay tuned for more exciting Cisco Silicon One developments.
Learn more about
architecture, devices, and benefits.
Additional Resources
Read my first blog on Silicon One: Building AI/ML Networks with Cisco Silicon One
Share:
