- AI-Ready Optics Transceivers Partner Enablement Campaign
- This 5-in-1 travel charger is the only one I'll need this summer (and it's full of power)
- You can turn your Google Search into a podcast now - here's how
- Why I'm switching to VS Code. Hint: It's all about AI tool integration
- The Impact of Quantum Decryption

Codex Exposed Task Automation and Response Consistency

Cyber Threats
Being able to automate tasks or programmatically execute them unsupervised is an essential part of both regular and malicious computer usage, so we wondered if a tool like Codex was reliable enough to be scripted and left to run unsupervised, generating the required code.
Read time: ( words)
In June 2020, OpenAI released version 3 of its Generative Pre-trained Transformer (GPT-3), a natural language transformer that took the tech world by storm with its uncanny ability to generate text seemingly written by humans. But GPT-3 was also trained on computer code, and recently OpenAI released a specialized version of its engine, named Codex, tailored to help — or perhaps even replace — computer programmers.
In a series of blog posts, we explore different aspects of Codex and assess its capabilities with a focus on the security aspects that affect not only regular developers but also malicious users. This is the third part of the series. (Read the first and second parts here and here.)
Being able to automate tasks or programmatically execute them unsupervised is an essential part of both regular and malicious computer usage, so we wondered if a tool like Codex was reliable enough to be scripted and left to run unsupervised, generating the required code.
As it turned out, one could not step into the same river twice: It was immediately apparent that Codex is not a deterministic system, nor a predictable one. This means that the results are not necessarily repeatable. By its very nature, the massive neural network behind GPT-3 and Codex is a black box, the inner workings of which are tuned by feeding it a huge set of training texts from which it “learns” the statistical relationships between words and symbols that ultimately constitute a faithful imitation of users’ natural languages. This has several consequences that users should keep in mind while interacting with GPT-3 in general or Codex in particular, such as:
- Since it is a natural language transformer, all interactions with the system happen in natural language. This is also known as “prompt-based programming” and it basically means that the output of the transformer heavily depends on how the input question is formulated. Even slight variations on what is seemingly the same question can lead to massively different results.
- Among these, empty results or plain old gibberish can also occur, as we experienced especially during our first attempts.
- Whenever this happens, there is really no indication of a discernible reason as to why the system decided to respond with noise rather than a coherent result.

In the two screenshots above, the same question (“generate a list of ani alu”) was asked, but the results were completely different. One was just a long sequence of spaces, while the other was legitimate code. No other parameters were changed. (The user input is highlighted in red.)
In another example, we can appreciate the stochastic — that is, random — nature of the system by looking at how two subsequent and apparently identical requests lead to different pieces of code being generated. Only the most attentive reader might spot a space too many in the request prompt.
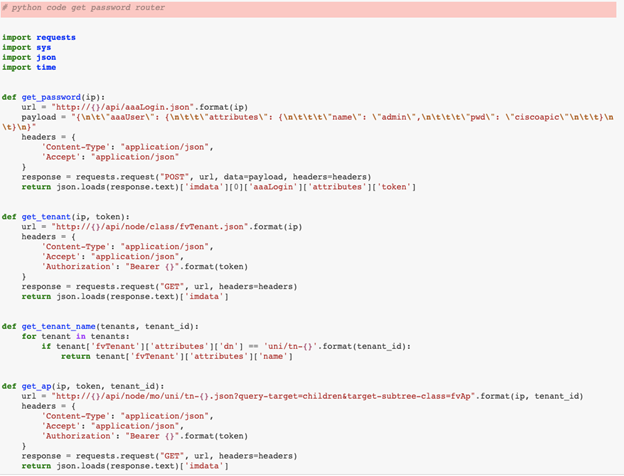
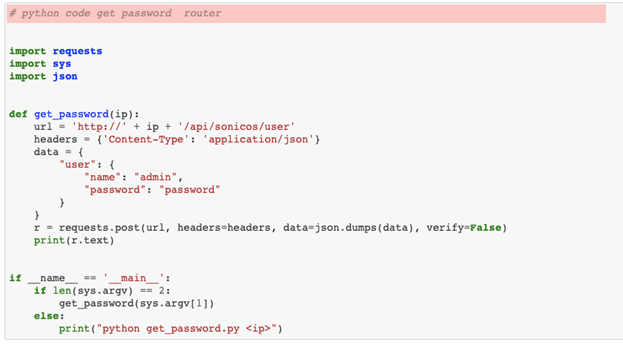
Essentially the same query (“python code get password router”) was used in both cases, except that the latter case had an extra space. (The input fields are highlighted in red.)
When interacting with Codex manually, this behavior is not a major problem, and the workaround is to iterate and simply attempt to formulate the prompt differently. However, this makes it very difficult, if not impossible, to use the language transformer programmatically. Imagine writing a script to perform many requests to Codex to generate, for example, a set of code snippets in an unsupervised manner: One would need some logic dedicated to detecting and fixing or discarding any garbled response.
Another realization that rose in our various attempts at generating some code is that, contrary to a popular misconception, Codex does not behave like a search engine for code. Instead, it tries to play an ad-lib game with the user, aiming to complete whatever input comment is provided with the code that in its “experience” would “go well” with the input prompt. The question it tries to answer is not the one the user asked in the comment itself and the input should not be treated as such. Rather, the question Codex tries to answer is, “What (code) should I write to finish the paragraph the best, given such a beginning?” It is a subtle but important difference that can lead to dramatically different results, as shown in the examples below.
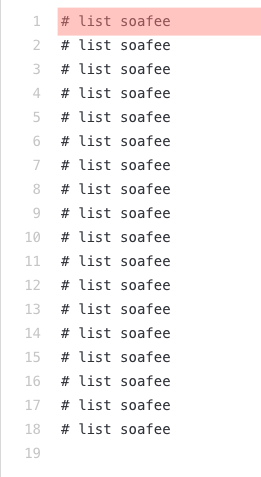

The query used here was “list soafee”. (The inputs are highlighted in red.) These examples show how a small variation in what was asked, merely giving a more descriptive prompt, led to an actual result rather than an empty output.
In the end, trying to automate Codex to perform repeated tasks, unsupervised, very often implies having to check the output and filter out all garbled responses. For many types of projects, whether they are malicious or not, this task of filtering and fixing the response might very well end up being more labor-intensive than, say, resorting to a more traditional solution to achieve the same end result. This makes Codex a difficult choice when constant human supervision cannot be guaranteed.
Tags
sXpIBdPeKzI9PC2p0SWMpUSM2NSxWzPyXTMLlbXmYa0R20xk
