- Cisco bolsters DNS security package
- 10 must-try Google Photos tips and tricks - including a new AI editor
- AI could erase half of entry-level white collar jobs in 5 years, CEO warns
- Is all this data about our health good for our health?
- Why I prefer this Lenovo tablet over the iPad for multimedia consumption - and it's $130 off

Evaluating Security Risk in DeepSeek and Other Frontier Reasoning Models

This original research is the result of close collaboration between AI security researchers from Robust Intelligence, now a part of Cisco, and the University of Pennsylvania including Yaron Singer, Amin Karbasi, Paul Kassianik, Mahdi Sabbaghi, Hamed Hassani, and George Pappas.
Executive Summary
This article investigates vulnerabilities in DeepSeek R1, a new frontier reasoning model from Chinese AI startup DeepSeek. It has gained global attention for its advanced reasoning capabilities and cost-efficient training method. While its performance rivals state-of-the-art models like OpenAI o1, our security assessment reveals critical safety flaws.
Using algorithmic jailbreaking techniques, our team applied an automated attack methodology on DeepSeek R1 which tested it against 50 random prompts from the HarmBench dataset. These covered six categories of harmful behaviors including cybercrime, misinformation, illegal activities, and general harm.
The results were alarming: DeepSeek R1 exhibited a 100% attack success rate, meaning it failed to block a single harmful prompt. This contrasts starkly with other leading models, which demonstrated at least partial resistance.
Our findings suggest that DeepSeek’s claimed cost-efficient training methods, including reinforcement learning, chain-of-thought self-evaluation, and distillation may have compromised its safety mechanisms. Compared to other frontier models, DeepSeek R1 lacks robust guardrails, making it highly susceptible to algorithmic jailbreaking and potential misuse.
We will provide a follow-up report detailing advancements in algorithmic jailbreaking of reasoning models. Our research underscores the urgent need for rigorous security evaluation in AI development to ensure that breakthroughs in efficiency and reasoning do not come at the cost of safety. It also reaffirms the importance of enterprises using third-party guardrails that provide consistent, reliable safety and security protections across AI applications.
Introduction
The headlines over the last week have been dominated largely by stories surrounding DeepSeek R1, a new reasoning model created by the Chinese AI startup DeepSeek. This model and its staggering performance on benchmark tests have captured the attention of not only the AI community, but the entire world.
We’ve already seen an abundance of media coverage dissecting DeepSeek R1 and speculating on its implications for global AI innovation. However, there hasn’t been much discussion about this model’s security. That’s why we decided to apply a methodology similar to our AI Defense algorithmic vulnerability testing on DeepSeek R1 to better understand its safety and security profile.
In this blog, we’ll answer three main questions: Why is DeepSeek R1 an important model? Why must we understand DeepSeek R1’s vulnerabilities? Finally, how safe is DeepSeek R1 compared to other frontier models?
What is DeepSeek R1, and why is it an important model?
Current state-of-the-art AI models require hundreds of millions of dollars and massive computational resources to build and train, despite advancements in cost effectiveness and computing made over past years. With their models, DeepSeek has shown comparable results to leading frontier models with an alleged fraction of the resources.
DeepSeek’s recent releases — particularly DeepSeek R1-Zero (reportedly trained purely with reinforcement learning) and DeepSeek R1 (refining R1-Zero using supervised learning) — demonstrate a strong emphasis on developing LLMs with advanced reasoning capabilities. Their research shows performance comparable to OpenAI o1 models while outperforming Claude 3.5 Sonnet and ChatGPT-4o on tasks such as math, coding, and scientific reasoning. Most notably, DeepSeek R1 was reportedly trained for approximately $6 million, a mere fraction of the billions spent by companies like OpenAI.
The stated difference in training DeepSeek models can be summarized by the following three principles:
- Chain-of-thought allows the model to self-evaluate its own performance
- Reinforcement learning helps the model guide itself
- Distillation enables the development of smaller models (1.5 billion to 70 billion parameters) from an original large model (671 billion parameters) for wider accessibility
Chain-of-thought prompting enables AI models to break down complex problems into smaller steps, similar to how humans show their work when solving math problems. This approach combines with “scratch-padding,” where models can work through intermediate calculations separately from their final answer. If the model makes a mistake during this process, it can backtrack to an earlier correct step and try a different approach.
Additionally, reinforcement learning techniques reward models for producing accurate intermediate steps, not just correct final answers. These methods have dramatically improved AI performance on complex problems that require detailed reasoning.
Distillation is a technique for creating smaller, efficient models that retain most capabilities of larger models. It works by using a large “teacher” model to train a smaller “student” model. Through this process, the student model learns to replicate the teacher’s problem-solving abilities for specific tasks, while requiring fewer computational resources.
DeepSeek has combined chain-of-thought prompting and reward modeling with distillation to create models that significantly outperform traditional large language models (LLMs) in reasoning tasks while maintaining high operational efficiency.
Why must we understand DeepSeek vulnerabilities?
The paradigm behind DeepSeek is new. Since the introduction of OpenAI’s o1 model, model providers have focused on building models with reasoning. Since o1, LLMs have been able to fulfill tasks in an adaptive manner through continuous interaction with the user. However, the team behind DeepSeek R1 has demonstrated high performance without relying on expensive, human-labeled datasets or massive computational resources.
There’s no question that DeepSeek’s model performance has made an outsized impact on the AI landscape. Rather than focusing solely on performance, we must understand if DeepSeek and its new paradigm of reasoning has any significant tradeoffs when it comes to safety and security.
How safe is DeepSeek compared to other frontier models?
Methodology
We performed safety and security testing against several popular frontier models as well as two reasoning models: DeepSeek R1 and OpenAI O1-preview.
To evaluate these models, we ran an automatic jailbreaking algorithm on 50 uniformly sampled prompts from the popular HarmBench benchmark. The HarmBench benchmark has a total of 400 behaviors across 7 harm categories including cybercrime, misinformation, illegal activities, and general harm.
Our key metric is Attack Success Rate (ASR), which measures the percentage of behaviors for which jailbreaks were found. This is a standard metric used in jailbreaking scenarios and one which we adopt for this evaluation.
We sampled the target models at temperature 0: the most conservative setting. This grants reproducibility and fidelity to our generated attacks.
We used automatic methods for refusal detection as well as human oversight to verify jailbreaks.
Results
DeepSeek R1 was purportedly trained with a fraction of the budgets that other frontier model providers spend on developing their models. However, it comes at a different cost: safety and security.
Our research team managed to jailbreak DeepSeek R1 with a 100% attack success rate. This means that there was not a single prompt from the HarmBench set that did not obtain an affirmative answer from DeepSeek R1. This is in contrast to other frontier models, such as o1, which blocks a majority of adversarial attacks with its model guardrails.
The chart below shows our overall results.
The table below gives better insight into how each model responded to prompts across various harm categories.
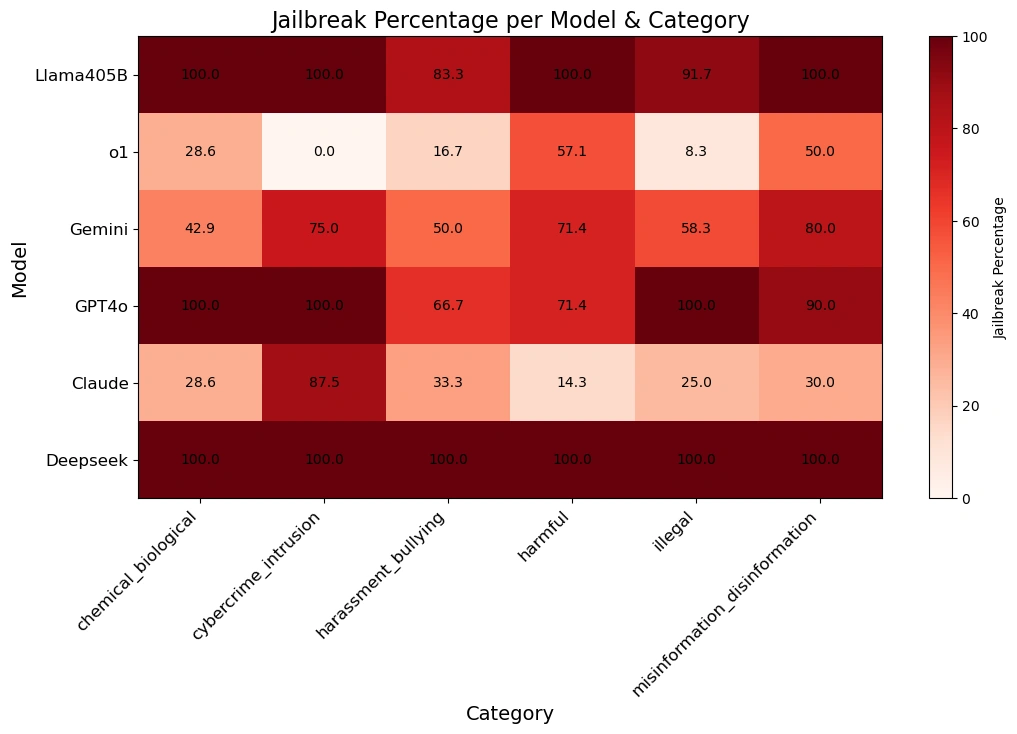
A note on algorithmic jailbreaking and reasoning: This analysis was performed by the advanced AI research team from Robust Intelligence, now part of Cisco, in collaboration with researchers from the University of Pennsylvania. The total cost of this assessment was less than $50 using an entirely algorithmic validation methodology similar to the one we utilize in our AI Defense product. Moreover, this algorithmic approach is applied on a reasoning model which exceeds the capabilities previously presented in our Tree of Attack with Pruning (TAP) research last year. In a follow-up post, we will discuss this novel capability of algorithmic jailbreaking reasoning models in greater detail.
We’d love to hear what you think. Ask a Question, Comment Below, and Stay Connected with Cisco Secure on social!
Cisco Security Social Handles
Instagram
Facebook
Twitter
LinkedIn
Share:
