- Learn with Cisco at Cisco Live 2025 in San Diego
- This Eufy robot vacuum has a built-in handheld vac - and just hit its lowest price
- I highly recommend this Lenovo laptop, and it's nearly 50% off
- Disney+ and Hulu now offer prizes, freebies, and other perks to keep you subscribed
- This new YouTube Shorts feature lets you circle to search videos more easily

LLM Everywhere: Docker for Local and Hugging Face Hosting | Docker

This post is written in collaboration with Docker Captain Harsh Manvar.
Hugging Face has become a powerhouse in the field of machine learning (ML). Their large collection of pretrained models and user-friendly interfaces have entirely changed how we approach AI/ML deployment and spaces. If you’re interested in looking deeper into the integration of Docker and Hugging Face models, a comprehensive guide can be found in the article “Build Machine Learning Apps with Hugging Face’s Docker Spaces.”
The Large Language Model (LLM) — a marvel of language generation — is an astounding invention. In this article, we’ll look at how to use the Hugging Face hosted Llama model in a Docker context, opening up new opportunities for natural language processing (NLP) enthusiasts and researchers.

Introduction to Hugging Face and LLMs
Hugging Face (HF) provides a comprehensive platform for training, fine-tuning, and deploying ML models. And, LLMs provide a state-of-the-art model capable of performing tasks like text generation, completion, and classification.
Leveraging Docker for ML
The robust Docker containerization technology makes it easier to package, distribute, and operate programs. It guarantees that ML models operate consistently across various contexts by enclosing them within Docker containers. Reproducibility is ensured, and the age-old “it works on my machine” issue is resolved.
Type of formats
For the majority of models on Hugging Face, two options are available.
Examples of quantization techniques used in AI model quantization include the GGML and GPTQ models. This can mean quantization either during or after training. By reducing model weights to a lower precision, the GGML and GPTQ models — two well-known quantized models — minimize model size and computational needs.
HF models load on the GPU, which performs inference significantly more quickly than the CPU. Generally, the model is huge, and you also need a lot of VRAM. In this article, we will utilize the GGML model, which operates well on CPU and is probably faster if you don’t have a good GPU.
We will also be using transformers and ctransformers in this demonstration, so let’s first understand those:
- transformers: Modern pretrained models can be downloaded and trained with ease thanks to transformers’ APIs and tools. By using pretrained models, you can cut down on the time and resources needed to train a model from scratch, as well as your computational expenses and carbon footprint.
- ctransformers: Python bindings for the transformer models developed in C/C++ with the GGML library.
Request Llama model access
We will utilize the Meta Llama model, signup, and request for access.
Create Hugging Face token
To create an Access token that will be used in the future, go to your Hugging Face profile settings and select Access Token from the left-hand sidebar (Figure 1). Save the value of the created Access Token.
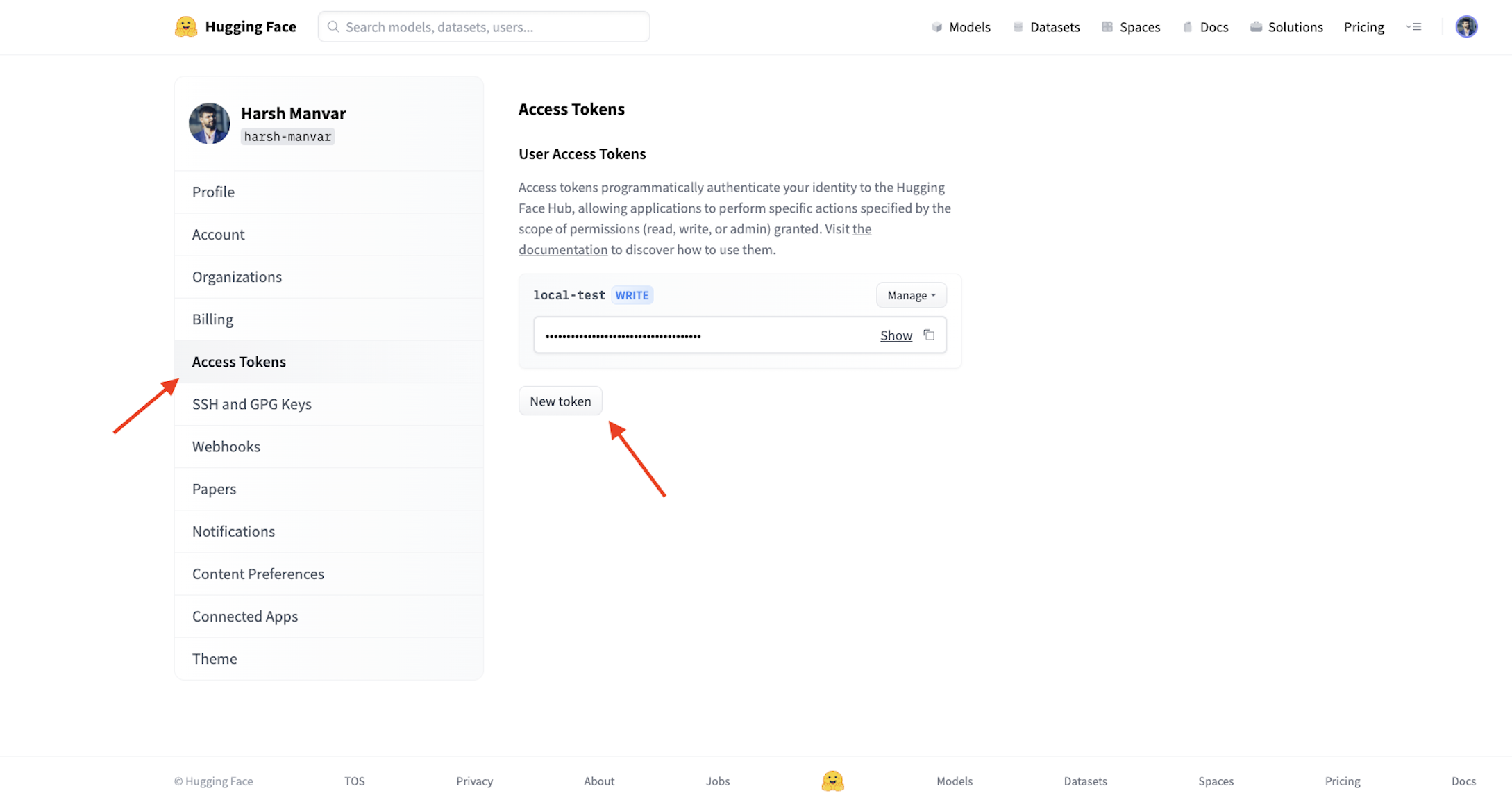
Setting up Docker environment
Before exploring the realm of the LLM, we must first configure our Docker environment. Install Docker first, following the instructions on the official Docker website based on your operating system. After installation, execute the following command to confirm your setup:
Quick demo
The following command runs a container with the Hugging Face harsh-manvar-llama-2-7b-chat-test:latest image and exposes port 7860 from the container to the host machine. It will also set the environment variable HUGGING_FACE_HUB_TOKEN to the value you provided.
docker run -it -p 7860:7860 --platform=linux/amd64
-e HUGGING_FACE_HUB_TOKEN="YOUR_VALUE_HERE"
registry.hf.space/harsh-manvar-llama-2-7b-chat-test:latest python app.py
- The
-itflag tells Docker to run the container in interactive mode and to attach a terminal to it. This will allow you to interact with the container and its processes. - The
-pflag tells Docker to expose port 7860 from the container to the host machine. This means that you will be able to access the container’s web server from the host machine on port 7860. - The
--platform=linux/amd64flag tells Docker to run the container on a Linux machine with an AMD64 architecture. - The
-e HUGGING_FACE_HUB_TOKEN="YOUR_VALUE_HERE"flag tells Docker to set the environment variableHUGGING_FACE_HUB_TOKENto the value you provided. This is required for accessing Hugging Face models from the container.
The app.py script is the Python script that you want to run in the container. This will start the container and open a terminal to it. You can then interact with the container and its processes in the terminal. To exit the container, press Ctrl+C.
Accessing the landing page
To access the container’s web server, open a web browser and navigate to http://localhost:7860. You should see the landing page for your Hugging Face model (Figure 2).
Open your browser and go to http://localhost:7860:
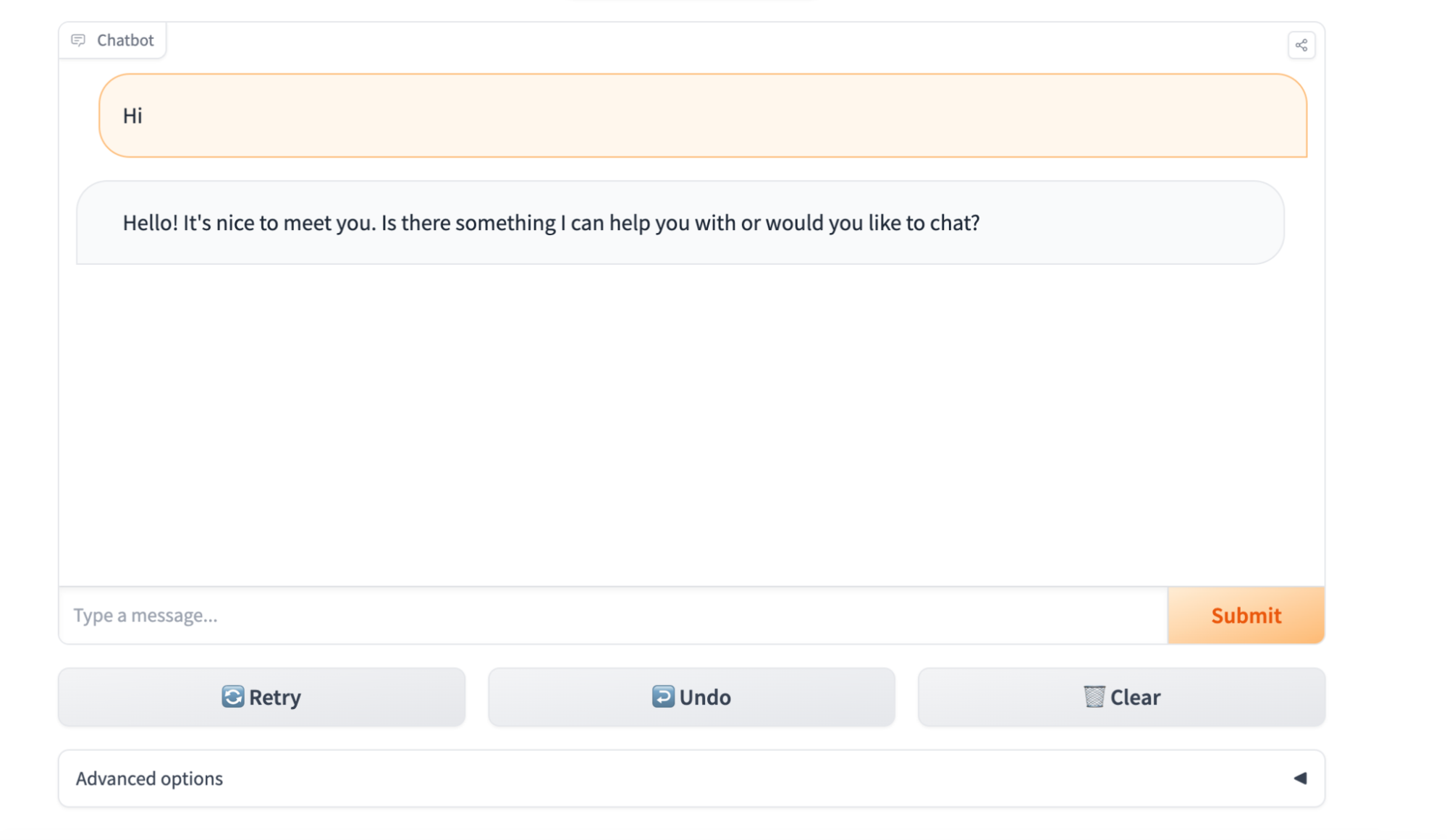
Getting started
Cloning the project
To get started, you can clone or download the Hugging Face existing space/repository.
git clone https://huggingface.co/spaces/harsh-manvar/llama-2-7b-chat-test
File: requirements.txt
A requirements.txt file is a text file that lists the Python packages and modules that a project needs to run. It is used to manage the project’s dependencies and to ensure that all developers working on the project are using the same versions of the required packages.
The following Python packages are required to run the Hugging Face llama-2-13b-chat model. Note that this model is large, and it may take some time to download and install. You may also need to increase the memory allocated to your Python process to run the model.
gradio==3.37.0
protobuf==3.20.3
scipy==1.11.1
torch==2.0.1
sentencepiece==0.1.99
transformers==4.31.0
ctransformers==0.2.27
File: Dockerfile
FROM python:3.9
RUN useradd -m -u 1000 user
WORKDIR /code
COPY ./requirements.txt /code/requirements.txt
RUN pip install --upgrade pip
RUN pip install --no-cache-dir --upgrade -r /code/requirements.txt
USER user
COPY --link --chown=1000 ./ /code
The following section provides a breakdown of the Dockerfile. The first line tells Docker to use the official Python 3.9 image as the base image for our image:
The following line creates a new user named user with the user ID 1000. The -m flag tells Docker to create a home directory for the user.
RUN useradd -m -u 1000 user
Next, this line sets the working directory for the container to /code.
It’s time to copy the requirements file from the current directory to /code in the container. Also, this line upgrades the pip package manager in the container.
RUN pip install --no-cache-dir --upgrade -r /code/requirements.txt
This line sets the default user for the container to user.
The following line copies the contents of the current directory to /code in the container. The --link flag tells Docker to create hard links instead of copying the files, which can improve performance and reduce the size of the image. The --chown=1000 flag tells Docker to change the ownership of the copied files to the user user.
COPY --link --chown=1000 ./ /code
Once you have built the Docker image, you can run it using the docker run command. This will start a new container running the Python 3.9 image with the non-root user user. You can then interact with the container using the terminal.
File: app.py
The Python code shows how to use Gradio to create a demo for a text-generation model trained using transformers. The code allows users to input a text prompt and generate a continuation of the text.
Gradio is a Python library that allows you to create and share interactive machine learning demos with ease. It provides a simple and intuitive interface for creating and deploying demos, and it supports a wide range of machine learning frameworks and libraries, including transformers.
This Python script is a Gradio demo for a text chatbot. It uses a pretrained text generation model to generate responses to user input. We’ll break down the file and look at each of the sections.
The following line imports the Iterator type from the typing module. This type is used to represent a sequence of values that can be iterated over. The next line imports the gradio library as well.
from typing import Iterator
import gradio as gr
The following line imports the logging module from the transformers library, which is a popular machine learning library for natural language processing.
from transformers.utils import logging
from model import get_input_token_length, run
Next, this line imports the get_input_token_length() and run() functions from the model module. These functions are used to calculate the input token length of a text and generate text using a pretrained text generation model, respectively. The next two lines configure the logging module to print information-level messages and to use the transformers logger.
from model import get_input_token_length, run
logging.set_verbosity_info()
logger = logging.get_logger("transformers")
The following lines define some constants that are used throughout the code. Also, the lines define the text that is displayed in the Gradio demo.
DEFAULT_SYSTEM_PROMPT = """"""
MAX_MAX_NEW_TOKENS = 2048
DEFAULT_MAX_NEW_TOKENS = 1024
MAX_INPUT_TOKEN_LENGTH = 4000
DESCRIPTION = """"""
LICENSE = """"""
This line logs an information-level message indicating that the code is starting. This function clears the textbox and saves the input message to the saved_input state variable.
logger.info("Starting")
def clear_and_save_textbox(message: str) -> tuple[str, str]:
return '', message
The following function displays the input message in the chatbot and adds the message to the chat history.
def display_input(message: str,
history: list[tuple[str, str]]) -> list[tuple[str, str]]:
history.append((message, ''))
logger.info("display_input=%s",message)
return history
This function deletes the previous response from the chat history and returns the updated chat history and the previous response.
def delete_prev_fn(
history: list[tuple[str, str]]) -> tuple[list[tuple[str, str]], str]:
try:
message, _ = history.pop()
except IndexError:
message = ''
return history, message or ''
The following function generates text using the pre-trained text generation model and the given parameters. It returns an iterator that yields a list of tuples, where each tuple contains the input message and the generated response.
def generate(
message: str,
history_with_input: list[tuple[str, str]],
system_prompt: str,
max_new_tokens: int,
temperature: float,
top_p: float,
top_k: int,
) -> Iterator[list[tuple[str, str]]]:
#logger.info("message=%s",message)
if max_new_tokens > MAX_MAX_NEW_TOKENS:
raise ValueError
history = history_with_input[:-1]
generator = run(message, history, system_prompt, max_new_tokens, temperature, top_p, top_k)
try:
first_response = next(generator)
yield history + [(message, first_response)]
except StopIteration:
yield history + [(message, '')]
for response in generator:
yield history + [(message, response)]
The following function generates a response to the given message and returns the empty string and the generated response.
def process_example(message: str) -> tuple[str, list[tuple[str, str]]]:
generator = generate(message, [], DEFAULT_SYSTEM_PROMPT, 1024, 1, 0.95, 50)
for x in generator:
pass
return '', x
Here’s the complete Python code:
from typing import Iterator
import gradio as gr
from transformers.utils import logging
from model import get_input_token_length, run
logging.set_verbosity_info()
logger = logging.get_logger("transformers")
DEFAULT_SYSTEM_PROMPT = """"""
MAX_MAX_NEW_TOKENS = 2048
DEFAULT_MAX_NEW_TOKENS = 1024
MAX_INPUT_TOKEN_LENGTH = 4000
DESCRIPTION = """"""
LICENSE = """"""
logger.info("Starting")
def clear_and_save_textbox(message: str) -> tuple[str, str]:
return '', message
def display_input(message: str,
history: list[tuple[str, str]]) -> list[tuple[str, str]]:
history.append((message, ''))
logger.info("display_input=%s",message)
return history
def delete_prev_fn(
history: list[tuple[str, str]]) -> tuple[list[tuple[str, str]], str]:
try:
message, _ = history.pop()
except IndexError:
message = ''
return history, message or ''
def generate(
message: str,
history_with_input: list[tuple[str, str]],
system_prompt: str,
max_new_tokens: int,
temperature: float,
top_p: float,
top_k: int,
) -> Iterator[list[tuple[str, str]]]:
#logger.info("message=%s",message)
if max_new_tokens > MAX_MAX_NEW_TOKENS:
raise ValueError
history = history_with_input[:-1]
generator = run(message, history, system_prompt, max_new_tokens, temperature, top_p, top_k)
try:
first_response = next(generator)
yield history + [(message, first_response)]
except StopIteration:
yield history + [(message, '')]
for response in generator:
yield history + [(message, response)]
def process_example(message: str) -> tuple[str, list[tuple[str, str]]]:
generator = generate(message, [], DEFAULT_SYSTEM_PROMPT, 1024, 1, 0.95, 50)
for x in generator:
pass
return '', x
def check_input_token_length(message: str, chat_history: list[tuple[str, str]], system_prompt: str) -> None:
#logger.info("check_input_token_length=%s",message)
input_token_length = get_input_token_length(message, chat_history, system_prompt)
#logger.info("input_token_length",input_token_length)
#logger.info("MAX_INPUT_TOKEN_LENGTH",MAX_INPUT_TOKEN_LENGTH)
if input_token_length > MAX_INPUT_TOKEN_LENGTH:
logger.info("Inside IF condition")
raise gr.Error(f'The accumulated input is too long ({input_token_length} > {MAX_INPUT_TOKEN_LENGTH}). Clear your chat history and try again.')
#logger.info("End of check_input_token_length function")
with gr.Blocks(css='style.css') as demo:
gr.Markdown(DESCRIPTION)
gr.DuplicateButton(value='Duplicate Space for private use',
elem_id='duplicate-button')
with gr.Group():
chatbot = gr.Chatbot(label='Chatbot')
with gr.Row():
textbox = gr.Textbox(
container=False,
show_label=False,
placeholder='Type a message...',
scale=10,
)
submit_button = gr.Button('Submit',
variant='primary',
scale=1,
min_width=0)
with gr.Row():
retry_button = gr.Button('Retry', variant='secondary')
undo_button = gr.Button('Undo', variant='secondary')
clear_button = gr.Button('Clear', variant='secondary')
saved_input = gr.State()
with gr.Accordion(label='Advanced options', open=False):
system_prompt = gr.Textbox(label='System prompt',
value=DEFAULT_SYSTEM_PROMPT,
lines=6)
max_new_tokens = gr.Slider(
label='Max new tokens',
minimum=1,
maximum=MAX_MAX_NEW_TOKENS,
step=1,
value=DEFAULT_MAX_NEW_TOKENS,
)
temperature = gr.Slider(
label='Temperature',
minimum=0.1,
maximum=4.0,
step=0.1,
value=1.0,
)
top_p = gr.Slider(
label='Top-p (nucleus sampling)',
minimum=0.05,
maximum=1.0,
step=0.05,
value=0.95,
)
top_k = gr.Slider(
label='Top-k',
minimum=1,
maximum=1000,
step=1,
value=50,
)
gr.Markdown(LICENSE)
textbox.submit(
fn=clear_and_save_textbox,
inputs=textbox,
outputs=[textbox, saved_input],
api_name=False,
queue=False,
).then(
fn=display_input,
inputs=[saved_input, chatbot],
outputs=chatbot,
api_name=False,
queue=False,
).then(
fn=check_input_token_length,
inputs=[saved_input, chatbot, system_prompt],
api_name=False,
queue=False,
).success(
fn=generate,
inputs=[
saved_input,
chatbot,
system_prompt,
max_new_tokens,
temperature,
top_p,
top_k,
],
outputs=chatbot,
api_name=False,
)
button_event_preprocess = submit_button.click(
fn=clear_and_save_textbox,
inputs=textbox,
outputs=[textbox, saved_input],
api_name=False,
queue=False,
).then(
fn=display_input,
inputs=[saved_input, chatbot],
outputs=chatbot,
api_name=False,
queue=False,
).then(
fn=check_input_token_length,
inputs=[saved_input, chatbot, system_prompt],
api_name=False,
queue=False,
).success(
fn=generate,
inputs=[
saved_input,
chatbot,
system_prompt,
max_new_tokens,
temperature,
top_p,
top_k,
],
outputs=chatbot,
api_name=False,
)
retry_button.click(
fn=delete_prev_fn,
inputs=chatbot,
outputs=[chatbot, saved_input],
api_name=False,
queue=False,
).then(
fn=display_input,
inputs=[saved_input, chatbot],
outputs=chatbot,
api_name=False,
queue=False,
).then(
fn=generate,
inputs=[
saved_input,
chatbot,
system_prompt,
max_new_tokens,
temperature,
top_p,
top_k,
],
outputs=chatbot,
api_name=False,
)
undo_button.click(
fn=delete_prev_fn,
inputs=chatbot,
outputs=[chatbot, saved_input],
api_name=False,
queue=False,
).then(
fn=lambda x: x,
inputs=[saved_input],
outputs=textbox,
api_name=False,
queue=False,
)
clear_button.click(
fn=lambda: ([], ''),
outputs=[chatbot, saved_input],
queue=False,
api_name=False,
)
demo.queue(max_size=20).launch(share=False, server_name="0.0.0.0")
The check_input_token_length and generate functions comprise the main part of the code. The generate function is responsible for generating a response given a message, a history of previous messages, and various generation parameters, including:
max_new_tokens: This is an integer that indicates the most tokens that the response-generating model is permitted to produce.temperature: This float value regulates how random the output that is produced is. The result is more random at higher values (like 1.0) and more predictable at lower levels (like 0.2).top_p: The nucleus sampling is determined by this float value, which ranges from 0 to 1. It establishes a cutoff point for the tokens’ cumulative probability.top_k: The number of next tokens to be considered is represented by this integer. A greater number results in a more concentrated output.
The UI component and running the API server are handled by app.py. Basically, app.py is where you initialize the application and other configuration.
File: Model.py
The Python script is a chat bot that uses an LLM to generate responses to user input. The script uses the following steps to generate a response:
- It creates a prompt for the LLM by combining the user input, the chat history, and the system prompt.
- It calculates the input token length of the prompt.
- It generates a response using the LLM and the following parameters:
max_new_tokens: Maximum number of new tokens to generate.temperature: Temperature to use when generating the response. A higher temperature will result in more creative and varied responses, but it may also result in less coherent responsestop_p: This parameter controls the nucleus sampling algorithm used to generate the response. A highertop_pvalue will result in more focused and informative responses, while a lower value will result in more creative and varied responses.top_k: This parameter controls the number of highest probability tokens to consider when generating the response. A highertop_kvalue will result in more predictable and consistent responses, while a lower value will result in more creative and varied responses.
The main function of the TextIteratorStreamer class is to store print-ready text in a queue. This queue can then be used by a downstream application as an iterator to access the generated text in a non-blocking way.
from threading import Thread
from typing import Iterator
#import torch
from transformers.utils import logging
from ctransformers import AutoModelForCausalLM
from transformers import TextIteratorStreamer, AutoTokenizer
logging.set_verbosity_info()
logger = logging.get_logger("transformers")
config = {"max_new_tokens": 256, "repetition_penalty": 1.1,
"temperature": 0.1, "stream": True}
model_id = "TheBloke/Llama-2-7B-Chat-GGML"
device = "cpu"
model = AutoModelForCausalLM.from_pretrained(model_id, model_type="llama", lib="avx2", hf=True)
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-chat-hf")
def get_prompt(message: str, chat_history: list[tuple[str, str]],
system_prompt: str) -> str:
#logger.info("get_prompt chat_history=%s",chat_history)
#logger.info("get_prompt system_prompt=%s",system_prompt)
texts = [f'<s>[INST] <<SYS>>n{system_prompt}n<</SYS>>nn']
#logger.info("texts=%s",texts)
do_strip = False
for user_input, response in chat_history:
user_input = user_input.strip() if do_strip else user_input
do_strip = True
texts.append(f'{user_input} [/INST] {response.strip()} </s><s>[INST] ')
message = message.strip() if do_strip else message
#logger.info("get_prompt message=%s",message)
texts.append(f'{message} [/INST]')
#logger.info("get_prompt final texts=%s",texts)
return ''.join(texts) def get_input_token_length(message: str, chat_history: list[tuple[str, str]], system_prompt: str) -> int:
#logger.info("get_input_token_length=%s",message)
prompt = get_prompt(message, chat_history, system_prompt)
#logger.info("prompt=%s",prompt)
input_ids = tokenizer([prompt], return_tensors='np', add_special_tokens=False)['input_ids']
#logger.info("input_ids=%s",input_ids)
return input_ids.shape[-1]
def run(message: str,
chat_history: list[tuple[str, str]],
system_prompt: str,
max_new_tokens: int = 1024,
temperature: float = 0.8,
top_p: float = 0.95,
top_k: int = 50) -> Iterator[str]:
prompt = get_prompt(message, chat_history, system_prompt)
inputs = tokenizer([prompt], return_tensors='pt', add_special_tokens=False).to(device)
streamer = TextIteratorStreamer(tokenizer,
timeout=15.,
skip_prompt=True,
skip_special_tokens=True)
generate_kwargs = dict(
inputs,
streamer=streamer,
max_new_tokens=max_new_tokens,
do_sample=True,
top_p=top_p,
top_k=top_k,
temperature=temperature,
num_beams=1,
)
t = Thread(target=model.generate, kwargs=generate_kwargs)
t.start()
outputs = []
for text in streamer:
outputs.append(text)
yield "".join(outputs)
To import the necessary modules and libraries for text generation with transformers, we can use the following code:
from transformers import AutoTokenizer, AutoModelForCausalLM
This will import the necessary modules for tokenizing and generating text with transformers.
To define the model to import, we can use:
model_id = "TheBloke/Llama-2-7B-Chat-GGML"
This step defines the model ID as TheBloke/Llama-2-7B-Chat-GGML, a scaled-down version of the Meta 7B chat LLama model.
Once you have imported the necessary modules and libraries and defined the model to import, you can load the tokenizer and model using the following code:
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id)
This will load the tokenizer and model from the Hugging Face Hub.The job of a tokenizer is to prepare the model’s inputs. Tokenizers for each model are available in the library. Define the model to import; again, we’re using TheBloke/Llama-2-7B-Chat-GGML.
You need to set the variables and values in config for max_new_tokens, temperature, repetition_penalty, and stream:
max_new_tokens: Most tokens possible, disregarding the prompt’s specified quantity of tokens.temperature: The amount that was utilized to modify the probability for the subsequent tokens.repetition_penalty: Repetition penalty parameter. 1.0 denotes no punishment.stream: Whether to generate the response text in a streaming manner or in a single batch.
You can also create the space and commit files to it to host applications on Hugging Face and test directly.
Building the image
The following command builds a Docker image for the llama-2-13b-chat model on the linux/amd64 platform. The image will be tagged with the name local-llm:v1.
docker buildx build --platform=linux/amd64 -t local-llm:v1 .
Running the container
The following command will start a new container running the local-llm:v1 Docker image and expose port 7860 on the host machine. The -e HUGGING_FACE_HUB_TOKEN="YOUR_VALUE_HERE" environment variable sets the Hugging Face Hub token, which is required to download the llama-2-13b-chat model from the Hugging Face Hub.
docker run -it -p 7860:7860 --platform=linux/amd64 -e HUGGING_FACE_HUB_TOKEN="YOUR_VALUE_HERE" local-llm:v1 python app.py
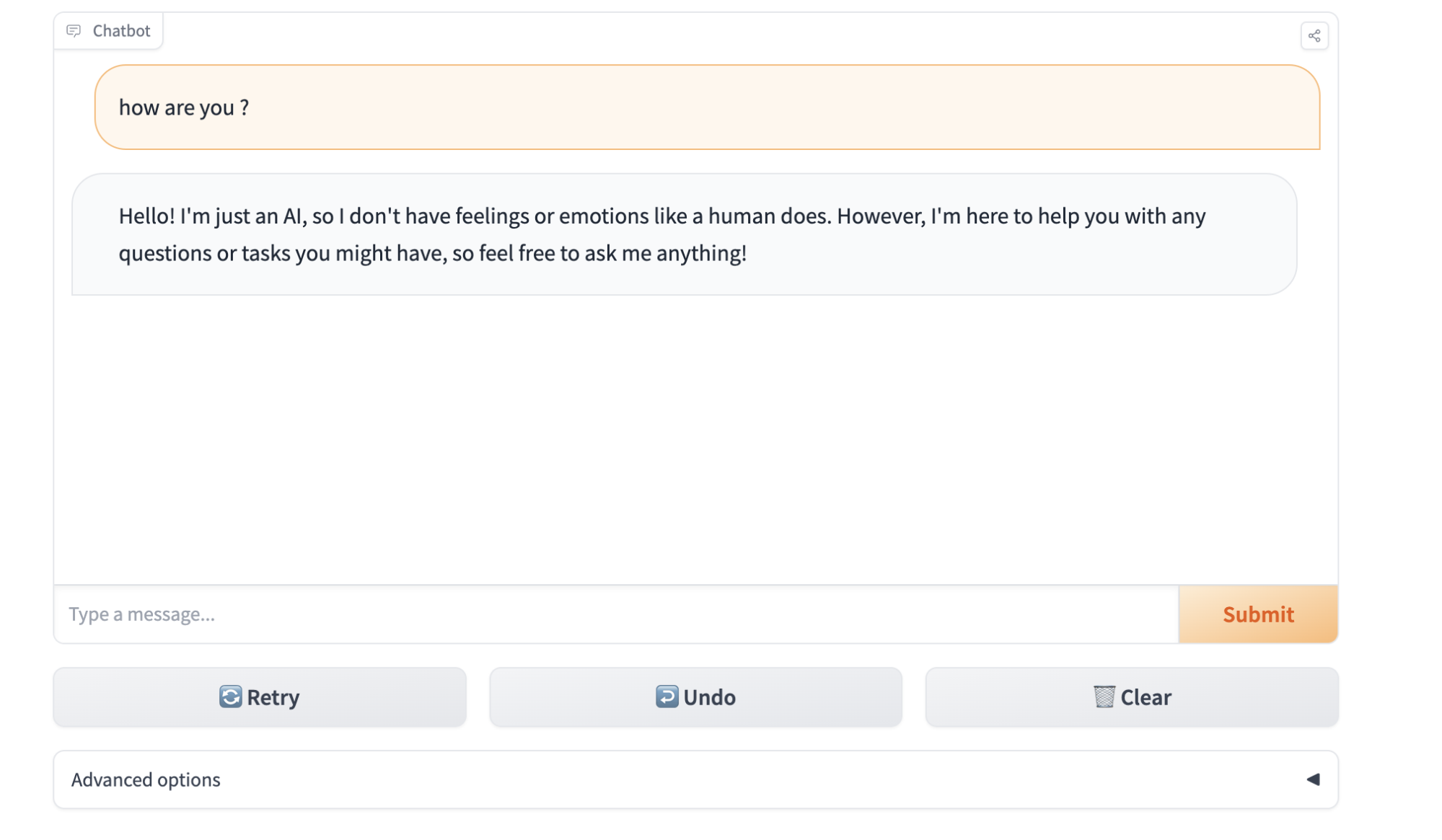
Next, open the browser and go to http://localhost:7860 to see local LLM Docker container output (Figure 3).
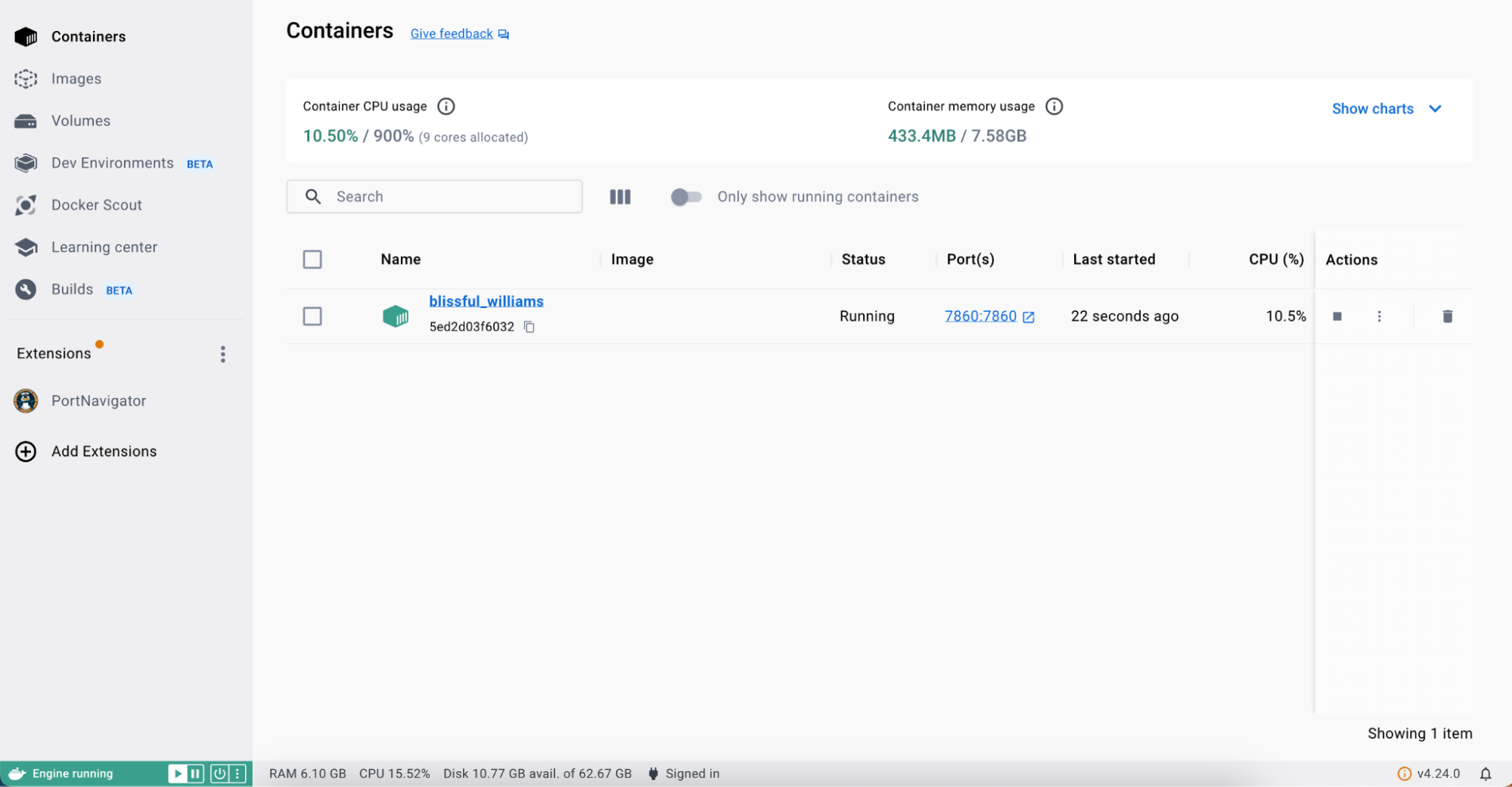
You can also view containers via the Docker Desktop (Figure 4).
Conclusion
Deploying the LLM GGML model locally with Docker is a convenient and effective way to use natural language processing. Dockerizing the model makes it easy to move it between different environments and ensures that it will run consistently. Testing the model in a browser provides a user-friendly interface and allows you to quickly evaluate its performance.
This setup gives you more control over your infrastructure and data and makes it easier to deploy advanced language models for a variety of applications. It is a significant step forward in the deployment of large language models.
