- Amazon is selling this 230-piece Craftsman toolset for just $99 ahead of Father's Day
- 7 browser features I can't live without that Chrome doesn't offer
- Save up to $400 on UltraGear OLED gaming monitors at LG
- Why Apple's best new AI features at WWDC 2025 will be deliciously seamless
- My top 3 distraction-free writing apps that helped me write dozens of novels

Market-Inspired GPU Allocation in AI Workloads: A Cybersecurity Use Case

Introduction
Over the last couple of years, advancements in Artificial Intelligence (AI) have driven an exponential increase in the demand for GPU resources and electrical energy, leading to a global scarcity of high-performance GPUs, such as NVIDIA’s flagship chipsets. This scarcity has created a competitive and costly landscape. Organizations with the financial capacity to build their own AI infrastructure pay substantial premiums to maintain operations, while others rely on renting GPU resources from cloud providers, which comes with equally prohibitive and escalating costs. These infrastructures often operate under a “one-size-fits-all” model, in which organizations are forced to pay for AI-supporting resources that remain underutilized during extended periods of low demand, resulting in unnecessary expenditures.
The financial and logistical challenges of sustaining such infrastructure are better illustrated by examples like OpenAI, which, despite having approximately 10 million paying subscribers for its ChatGPT service, reportedly incurs significant daily losses due to the overwhelming operational expenses attributed to the tens of thousands of GPUs and energy used to support AI operations. This raises critical concerns about the long-term sustainability of AI, particularly as demand and costs for GPUs and energy continue to rise.
Such costs can be significantly decreased by developing effective mechanisms that can dynamically discover and allocate GPUs in a semi-decentralized fashion that caters to the specific requirements of individual AI operations. Modern GPU allocation solutions must adapt to the varying nature of AI workloads and provide customized resource provisioning to avoid unnecessary idle states. They also need to incorporate efficient mechanisms for identifying optimal GPU resources, especially when resources are constrained. This can be challenging as GPU allocation systems must accommodate the changing computational needs, priorities, and constraints of different AI tasks and implement lightweight and efficient methods to enable quick and effective resource allocation without resorting to exhaustive searches.
In this paper, we propose a self-adaptive GPU allocation framework that dynamically manages the computational needs of AI workloads of different assets / systems by combining a decentralized agent-based auction mechanism (e.g. English and Posted-offer auctions) with supervised learning techniques such as Random Forest.
The auction mechanism addresses the scale and complexity of GPU allocation while balancing trade-offs between competing resource requests in a distributed and efficient manner. The choice of auction mechanism can be tailored based on the operating environment as well as the number of providers and users (bidders) to ensure effectiveness. To further optimize the process, blockchain technology is incorporated into the auction mechanism. Using blockchain ensures secure, transparent, and decentralized resource allocation and a broader reach for GPU resources. Peer-to-peer blockchain projects (e.g., Render, Akash, Spheron, Gpu.net) that utilize idle GPU resources already exist and are widely used.
Meanwhile, the supervised learning component, specifically the Random Forest classification algorithm, enables proactive and automated decision-making by detecting runtime anomalies and optimizing resource allocation strategies based on historical data. By leveraging the Random Forest classifier, our framework identifies efficient allocation plans informed by past performance, avoiding exhaustive searches and enabling tailored GPU provisioning for AI workloads.
The Use of Market in the GPU Allocation Framework
Services and GPU resources can adapt to the changing computational needs of AI workloads in dynamic and shared environments. AI tasks can be optimized by selecting appropriate GPU resources that best meet their evolving requirements and constraints. The connection between GPU resources and AI services is critical (Figure 1), as it captures not only the computational overhead imposed by AI tasks but also the efficiency and scalability of the solutions they provide. A unified model can be applied: each AI workload goal (e.g., training large language models) can be broken down into sub-goals, such as reducing latency, optimizing energy efficiency, or ensuring high throughput. These sub-goals can then be matched with GPU resources most suitable to support the overall AI objective.

Given the multi-tenant and shared nature of Cloud-based and blockchain enabled AI infrastructure, along with the high demand in GPUs, any allocation solution must be designed with scalable architecture. Market-inspired methodologies present a promising solution to this problem, offering an effective optimization mechanism for continuously satisfying the varying computational requirements of multiple AI tasks. These market-based solutions empower both users and providers to independently make decisions that maximize their use, while regulating the supply and demand of GPU resources, achieving equilibrium. In scenarios with limited GPU availability, auction mechanisms can facilitate effective allocation by prioritizing resource requests based on urgency (reflected in bidding prices), ensuring that high-priority AI tasks receive the necessary resources.
Market models along with blockchain also bring transparency to the allocation process by establishing systematic procedures for trading and mapping GPU resources to AI workloads and sub-goals. Finally, the adoption of market principles can be seamlessly integrated by AI service providers, operating either on Cloud or blockchain, reducing the need for structural changes and minimizing the risk of disruptions to AI workflows.
Framework Overview (Using an Example)
Given our expertise in cybersecurity, we explore a GPU allocation scenario for a forensic AI system designed to support incident response during a cyberattack. “Company Z” (fictitious), a multinational financial services firm operating in 20 countries, manages a distributed IT infrastructure with highly sensitive data, making it a prime target for threat actors. To enhance its security posture, Company Z deploys a forensic AI system that leverages GPU acceleration to rapidly analyze and respond to incidents.
This AI-driven system consists of autonomous agents embedded across the company’s infrastructure, continuously monitoring runtime security requirements through specialized sensors. When a cyber incident occurs, these agents dynamically adjust security operations, leveraging GPUs and other computational resources to process threats in real time. However, outside of emergencies, the AI system primarily functions in a training and reinforcement learning capacity, making a dedicated AI infrastructure both costly and inefficient. Instead, Company Z adopts an on-demand GPU allocation model, ensuring high-performance, AI-driven, forensic analysis while minimizing unnecessary resource waste. For the purposes of this example, we operate under the following assumptions:
Incident Overview
Company Z is under a ransomware attack affecting its internal databases and client records. The attack disrupts normal operations and threatens to leak and encrypt sensitive data. The forensic AI system needs to analyze the attack in real time, identify its root-cause, assess its impact, and recommend mitigation steps. The forensic AI system requires GPUs for computationally intensive tasks, including the analysis of attack patterns in various log files, analysis of encrypted data and assistance with guidance on recovery activities. The AI system relies on cloud-based and peer-to-peer blockchain GPU resources providers, which offer high-performance GPU instances for tasks such as deep learning model-based inference, data mining, and anomaly detection (Figure 2).
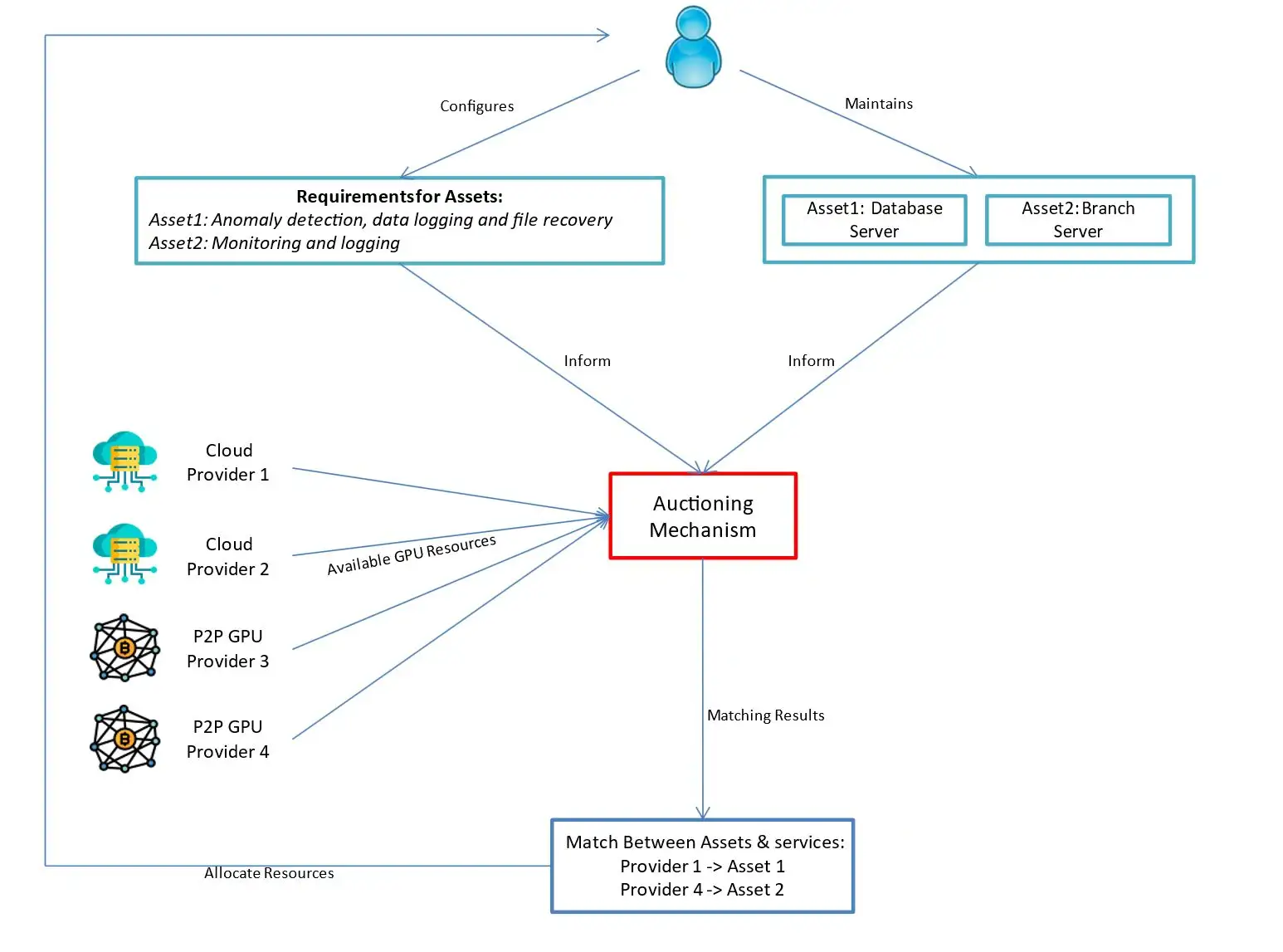
Dynamic Asset Needs
We take an asset centric approach to security to ensure we tailor GPU usage per system and cater to its exact needs, instead of promoting a one-solution-fits-all that can be more costly. In this scenario the assets considered include Company Z’s servers affected by the ransomware attack that need immediate forensic analysis. Each asset has a set of AI-related computational requirements based on the urgency of the response, sensitivity of the data, and severity of the attack. For example:
- The primary database server stores customer financial data and requires intensive GPU resources for anomaly detection, data logging and file recovery operations.
- A branch server, used for operational purposes, has lower urgency and requires minimal GPU resources for routine monitoring and logging tasks.
Initial Conditions
The forensic AI system begins by analyzing the ransomware’s root cause and lateral movement patterns. Company Z’s primary database server is classified as a critical asset with high computational demands, while the branch server is categorized as a medium-priority asset. The GPUs initially allocated are sufficient to perform these tasks. However, as the attack progresses, the ransomware begins to target encrypted backups. This is detected by the deployed agents which trigger a re-prioritization of resource allocation.
Adaptation and Decision Making
The forensic AI system uses a Random Forest classifier to analyze the changing conditions captured by agent sensors in real-time. It evaluates several factors:
- The urgency of tasks (e.g., whether the ransomware is actively encrypting more files).
- The sensitivity of the data (e.g., customer financial records vs. operational logs).
- Historical patterns of similar attacks and the associated GPU requirements.
- Historical analysis of incident responder activities on ransomware cases and their associated responses.
Based on these inputs, the system dynamically determines new resource allocation priorities. For instance, it may decide to allocate additional GPUs to the primary database server to expedite anomaly detection, system containment and data recovery while reducing the resources assigned to the branch server.
Market-Inspired GPU Allocation
Given the scarcity of GPUs, the system leverages a decentralized agent-based auction mechanism to acquire additional resources from Cloud and peer-to-peer blockchain providers. Each agent submits a bidding price per asset, reflecting its computational urgency. The primary database server submits a high bid due to its critical nature, while the branch server submits a lower bid. These bids are informed by historical data, ensuring efficient use of available resources. The GPU providers respond with a variation of the Posted Offer auction. In this model, providers set GPU prices and the number of available instances for a specific time. Assets with the highest bids (indicating the most urgent needs) are prioritized for GPU allocation, against the bids of other users and their assets in need of GPU resources.
As such, the primary database server successfully acquires additional GPUs due to its higher bidding price, prioritizing file recovery recommendations and anomaly detection, over the branch server, with its lower bid, reflecting a low priority task that is queued to wait for available GPU resources.
Evolving Requirements
As the ransomware attack further spreads, the sensors detect this activity. Based on historical patterns of similar attacks and their associated GPU requirements a new high-priority task for analyzing and protecting encrypted backups to prevent data loss has been created. This task introduces a new computational requirement, prompting the system to submit another bid for GPUs. The Random Forest algorithm identifies this task as critical and assigns a higher bidding price based on the sensitivity of the impacted data. The auction mechanism ensures that GPUs are dynamically allocated to this task, maintaining a balance between cost and urgency. Through this adaptive process, the forensic AI system successfully prioritizes GPU resources for the most critical tasks. Ensuring that Company Z can quickly mitigate the ransomware attack and guide incident responders and security analysts in recovering sensitive data and restoring operations.
Security Considerations
Outsourcing GPU computation introduces risks related to data confidentiality, integrity, and availability. Sensitive data transmitted to external providers may be exposed to unauthorized access, either through insider threats, misconfigurations, or side-channel attacks.
Additionally, malicious actors could manipulate computational results, inject false data, or interfere with resource allocation by inflating bids. Availability risks also arise if an attacker outbids critical assets, delaying essential processes like anomaly detection or file recovery. Regulatory concerns further complicate outsourcing, as data residency and compliance laws (e.g., GDPR, HIPAA) may restrict where and how data is processed.
To mitigate these risks, where performance allows, we leverage encryption techniques such as homomorphic encryption to enable computations on encrypted data without exposing raw information. Trusted Execution Environments (TEEs) like Intel SGX provide secure enclaves that ensure computations remain confidential and tamper-proof. For integrity, zero-knowledge proofs (ZKPs) allow verification of correct computation without revealing sensitive details. In cases where large amounts of data need to be processed, differential privacy techniques can be used to conceal individual data points in datasets by adding controlled random noise. Additionally, blockchain-based smart contracts can enhance auction transparency, preventing price manipulation and unfair resource allocation.
From an operational perspective, implementing a multi-cloud or hybrid strategy reduces dependency on a single provider, improving availability and redundancy. Strong access controls and monitoring help detect unauthorized access or tampering attempts in real-time. Finally, enforcing strict service-level agreements (SLAs) with GPU providers ensures accountability for performance, security, and regulatory compliance. By combining these mitigations, organizations can securely leverage external GPU resources while minimizing potential threats.
Conceptual Market-based Architecture
This section provides a high-level analysis of the entities and operation phases of the proposed framework.
Agents
Agents are autonomous entities that represent users in the “GPU market”. An agent is responsible for using their sensors to monitor changes in the run-time AI goals and sub-goals of assets and trigger adaptation for resources. By maintaining data records for each AI operation, it is feasible to construct training datasets to inform the Random Forest algorithm to replicate such behavior and allocate GPUs in an automated manner. To adapt, the Random Forest algorithm examines the recorded historical data of a user and its assets to discover correlations between previous AI operations (including their associated GPU usage) and the existing situation. The results from the Random Forest algorithm are then used to construct a specification, called a bid, which reflects the exact AI needs and supporting GPU resources. The bid consists of the different attributes that are dependent on the problem space. Once a bid is formed, it is forwarded to the coordinator (auctioneer) for auctioning.
GPU Resource Providers (GRP)
Cloud service and peer-to-peer GPU providers are vendors that trade their GPU resources in the market. They are responsible for publicly announcing their offers (called asks) to the coordinator. The asks comprise a specification of the traded resources along with the price that they want to sell them at. In case of a match between an ask and a bid, the GRP allocates the required GPU resources to the winning agent to support their AI operations. Thus, each user has access to different configurations of GPU resources that may be provided by different GRPs.
Coordinator
The coordinator is a centralized software system that functions as both an auctioneer and a market regulator, facilitating the allocation of GPU resources. Positioned between agents and GPU resource providers (GRPs), it manages trading rounds by collecting and matching bids from agents with provider offers. Once the auction process is finalized, the coordinator no longer interacts directly with users and providers. However, it continues to oversee compliance with Service Level Agreements (SLAs) and ensures that allocated resources are properly assigned to users as agreed.
System Operation Phases
The proposed framework consists of four (4) phases operating in a continuous cycle. Starting with monitoring that passes all relevant data for analysis informing the adaptation process, which in turn triggers feedback (allocation of required resources) meeting the changing AI operational requirements. Once a set of AI operational requirements are met, the monitoring phase starts again to detect new changes. The operational phases are as follow:
Monitor Phase
Sensors operate on the agent side to detect changes in security. The type of data collected varies depending on the specific problem being addressed (security or otherwise). For example, in the case of AI-driven threat detection, relevant changes impacting security might include:
Behavioral indicators:
- Process Execution Patterns: Monitoring unexpected or suspicious processes (e.g., execution of PowerShell scripts, unusual system calls).
- Network Traffic Anomalies: Detecting abnormal spikes in data transfer, communication with known malicious IPs, or unauthorized protocol usage.
- File Access and Modification Patterns: Identifying unauthorized file encryption (potential ransomware), unusual deletions, or repeated failed access attempts.
- User Activity Deviations: Analyzing deviations in system usage patterns, such as excessive privilege escalations, rapid data exfiltration, or abnormal working hours.
Content-based threat indicators:
- Malicious File Signatures: Scanning for known malware hashes, embedded exploits, or suspicious scripts in documents, emails, or downloads.
- Code and Memory Analysis: Detecting obfuscated code execution, process injection, or suspicious memory manipulations (e.g., Reflective DLL Injection, shellcode execution).
- Log File Anomalies: Identifying irregularities in system logs, such as log deletion, event suppression, or manipulation attempts.
Anomaly-based detection:
- Unusual Privilege Escalations: Tracking unexpected admin access, unauthorized privilege elevation, or lateral movement across systems.
- Resource Consumption Spikes: Monitoring unexplained high CPU/GPU usage, potentially indicating cryptojacking or denial-of-service (DoS) attacks.
- Data Exfiltration Patterns: Detecting large outbound data transfers, unusual data compression, or encrypted payloads sent to external servers.
Threat intelligence and correlation:
- Threat Feed Integration: Matching observed network behavior with real-time threat intelligence sources for known indicators of compromise (IoCs).
The data collected by the sensors is then fed into a watchdog process, which continuously monitors for any changes that could impact AI operations. This watchdog identifies shifts in security conditions or system behavior that may influence how GPU resources are allocated and consumed. For instance, if an AI agent detects an unusual login attempt from a high-risk location, it may require additional GPU resources to perform more intensive threat analysis and recommend appropriate activities for enhanced security.
Analysis Phase
During the analysis phase the data recorded from the sensors are examined to determine if the existing GPU resources can satisfy the runtime AI operational goals and sub-goals of an asset. In case where they are deemed insufficient adaptation is triggered. We adopt a goal-oriented approach to map security goals to their sub-goals. Critical changes to the dynamics of one or more interrelated sub-goals can trigger the need for adaptation. As adaptation is expensive, the frequency of adaptation can be determined by considering the extent to which the security goals and sub-goals diverge from the tolerance level.
Adaptation Phase
Adaptation involves bid formulation by agents, ask formulation by GPU providers, and the auctioning process to determine optimal matches. It also includes the allocation of GPU resources to users. The adaptation process operates as follows.
Bid Formulation
Adaptation initiates with the creation of a bid that requests the discovery, selection and allocation of GPU resources from different GRPs in the market. The bid is constructed with the assistance of the Random Forest algorithm which identifies the optimal course of action for adaptation based on previously encountered AI operations and their GPU usage. The use of ensemble classifiers, such as Random Forest, allows for mitigating bias and data overfitting due to their high variance. The constructed bids consist of the following attributes: i) the asset linked with AI operations; ii) the criticality of the operations; iii) the sub-goals that require support; iv) an approximate amount of GPU resources that will be utilized and v) the highest price that a user is willing to pay (can be calculated by taking the average value of all similar historical bids).
To determine how the choice of an auction can affect the cost of a solution for users, the proposed framework considers two dominant market mechanisms, namely the English auction and a variant of the Posted-offer auction model. Consequently, we use two different methods to calculate the bidding prices when forming bids. Our modified Posted Offer auction model is founded on a take-it-or-leave-it basis. In this model, the GRPs publicly announce the trading resources along with their associated costs for a certain trading period. During the trading period, agents are selected (one at a time) in descending order based on their bidding prices (instead of being chosen randomly) and allowed to accept or decline GRP offers. By introducing user bidding prices in the Posted Offer model, it is possible for the self-adaptive system to determine if a user can afford to pay a seller’s requested price, hence automating the selection process. As well as using bidding prices as a heuristic for ranking / selecting users based on the criticality of their requests. The auctioning round continues until all buyers have acquired service, or until all offered GPU resources have been allocated. Agents determine their bidding prices in Posted Offer by calculating the average value of all historical bidding prices with similar nature and criticality and then increase or decrease that value by a percentage “p”. The calculated bidding price is the highest price that a user is willing to bid on in an auction. Once the bidding price is calculated, the agent adds the price along with the other required attributes in a bid.
Similarly, the English auction procedure follows similar steps to the Posted Offer model to calculate bidding prices. In the English auction model, the bidding price initiates at a low price (established by the GRPs) and then raises incrementally, such as progressively higher bids are solicited until the auction is closed, or no higher bids are received. Therefore, each agent calculates its highest bidding price by considering the closing prices of completed auctions, in contrast to the fixed bidding prices used in the Posted Offer model.
Ask Formulation
GRPs on their side form their offers / asks which they forward to the coordinator for auctioning. GRPs determine the price of their GPU resources based on the historical data of submitted asks. A potential way to calculate the selling price is to take the average value of previously submitted ask prices and then subtract or add a percentage “p” on that value, depending on the profit margin a GRP wants to make. Once the selling price is calculated, the agents encapsulate the price along with a specification of the offered resources in an ask. Upon creation of the bid, it is forwarded to the auction coordinator.
Auctioning
Once bids and asks are received, the coordinator enters them in an auction to discover GPU resources that can best satisfy the AI operational goals and sub-goals of different assets and users, while catering for optimal costs. Depending on the method selected for calculating the bid and ask prices (i.e., Posted Offer or English auction), there is an analogous procedure for auctioning.
In the case where the Posted Offer methodology is employed, the coordinator discovers GRPs that can support the runtime AI goals and sub-goals of an asset / user by comparing the resource specification in an ask with the bid specification. In particular, the coordinator compares the: amount of GPU resources and price to determine the suitability of a service for an agent. In the case where an ask violates any of the specified requirements and constraints (e.g., a service offers inadequate computational resources) of an asset, the ask is eliminated. Upon elimination of all unsuitable asks, the coordinator sorts agents in a descending price order to rank them based on the criticality of their bids / requests. Following, the auctioneer selects agents (one at a time) starting from the top of the list to allow them to purchase the needed resources until all agents are served or until all available units are sold.
In the occasion where the English auction is used, the coordinator discovers all on-going auctions that satisfy the: computational requirements and bidding price and sets a bid on behalf of the agent. The bidding price reflects the current highest price in an auction plus a bid increment value “p”. The bid increment price is the minimum amount by which an agent’s bid can be raised to become the highest bidder. The bid increment value can be determined based on the highest bid in an auction. These values are case specific, and they can be altered by agents according to their runtime needs and the market prices. In the occasion where a rival agent tries to outbid the winning agent, the out-bid agent automatically increases its biding price to remain the highest bidder, whilst ensuring that the highest price specified in its bid is not violated. The winning auction, in which a match occurs, is the one in which an agent has set a bid and, upon completion of the auction round, has remained the highest bidder. If a match occurs and the agent has set a bid to more than one ongoing auction that trades similar services/resources, these bids are discarded. Submitting multiple bids to more than one auction that trades similar resources is permitted to increase the likelihood of a match occurring.
Feedback Phase
Once a match occurs, the feedback phase is initiated, during which the coordinator notifies the winning GRP and agent to commence the trade. The agent is requested to forward the payment for the won resources to the GRP. The transaction is recorded by the coordinator to ensure that no party will lie concerning the validity of the payment and allocation. In the case where the auctioning was performed based on the English auction, the agent needs to pay the price of the second highest bid plus a defined bid increment, whereas if the Posted Offer auction was used the fixed price set by a GRP is paid. Once payment is received, the Service Provider releases the requested resources. Resource allocation can be performed in two ways, depending on the GRP: either through a cloud container providing access to all GPU resources within the environment, or by creating a network drive that enables a direct, local interface to the user’s system. The coordinator is paid for its auctioning services by adding a small commission fee for every successful match which is equally split between the winning agent and GRP.
We’d love to hear what you think! Ask a question, comment below, and stay connected with Cisco Security on social media.
Cisco Security Social Channels
Share:
