- Kali Linux gets a UI refresh, new tools, and an updated car hacking toolset
- How the Sandwich Generation Can Fight Back Against Scams | McAfee Blog
- Buy a Samsung Galaxy Watch 7 on sale and get a free SmartTag2 Bluetooth tracker - here's how
- Cisco capitalizes on Isovalent buy, unveils new load balancer
- I upgraded to Android 16 - here's what I love and what's still missing

Troubleshooting puzzle: What caused the streaming to degrade?

You’ve just been given the task of solving a network problem that has been unresolved for many months. Where do you start? Is it a solvable problem or is it just the way the network works? Maybe you’ve encountered a limitation on how network protocols function.
What follows is an account of just such a problem that stumped many good network engineers for months and how it was resolved by NetCraftsmen’s Samuel Bickham. It may provide tips for solving problems you face down the road. As Bickham says, “Troubleshooting is kinda like a magic trick: It’s impressive until it’s explained.”
A customer contacted NetCraftsmen to ask if we could diagnose a networking problem that affected only a few applications and a subset of employees on an intermittent basis.
Some, but not all applications reliant upon TCP internet streaming data had suffered degraded performance for nearly 10 months. The most obvious symptoms were choppy voice and video dropouts, indicating something was happening to in-bound traffic. To add to the confusion, problematic performance seemed to occur only for employees whose streaming data was traversing a higher throughput path, but not observed for employees traversing a lower throughput path. Interestingly, the affected applications were running on systems with hard-wired connections. Wireless devices were not experiencing the problem.
These types of problems are very challenging to solve. Their intermittent nature and counter-intuitive symptoms makes it difficult to identify and pinpoint what causes them. In this case, the customer and previous consultants attributed the problem to the physical firewalls performing application inspection of real-time streaming applications used by hard-wired endpoints.
Dual firewalls
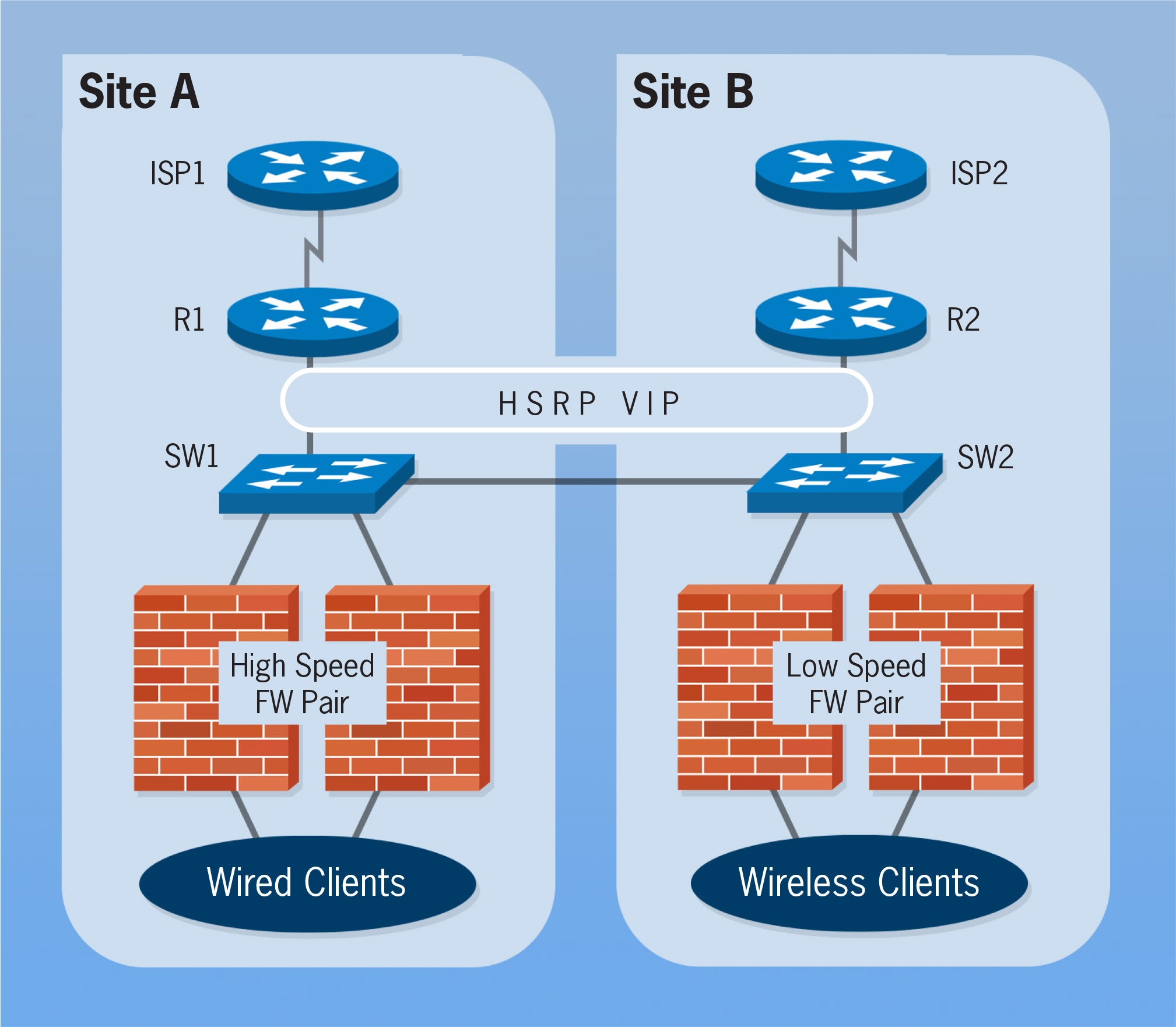
The network topology was based on a common design paradigm, shown below. A pair of firewalls were installed at each of two data centers. Each firewall was connected to a DMZ switch and router that connected out to the global internet via separate ISPs. The firewalls at Site A were capable of handling three times the traffic of those at Site B when performing Layer 7 inspection. There was plenty of firewall capacity for the traffic volume. Internally, the hot-standby routing protocol (HSRP) was used to provide a resilient next-hop address for outbound network traffic at the internet edge.
 Rob Schultz
Rob SchultzBGP was used to exchange network reachability information with each ISP for the customer’s assigned network address space. Using a /20 mask covered 4096 total addresses, and included address space from both sites. BGP community strings were used to perform ingress path selection, a common practice that requires that the customer and ISP agree on the community string (a prefix number that serves as a tag) and what the ISP’s network equipment should do when it is received.
The customer also employed network address translation (NAT) on two network address ranges (each was a /25 mask that translated up to 128 addresses), one range for each ISP. These addresses were within the /20 address range assigned to the customer. The BGP configuration would cause packet flows for wired clients to use ISP1 and wireless clients to use the path via ISP2.
This configuration had been working for several years. Something had obviously changed, but what was it? Was a firewall update to blame? It wasn’t clear.
The analysis
No one understood why some applications were not performing as desired and for only some employees. The affected flows were transiting the higher performance firewalls. Why was the problem not apparent on the path supported by the lower performance firewalls? Why weren’t all applications affected? There was no indication of link errors or packet loss that would indicate congestion. It didn’t make sense.
All symptoms pointed to a problem with the firewalls, but no one, even the vendor’s experts, could find anything wrong. There was some weirdness with the SSL flow queue counters on the firewalls, but that didn’t seem to account for the problem and the firewall vendor couldn’t explain what the counters were reporting. It may have just been a bug in the statistics report and ultimately wasn’t the problem, but it certainly added another question to the diagnosis.
Bickham spent some time validating the prior analysis. The streaming applications were still experiencing problems (it had been nearly ten months since it started). It still wasn’t clear what was happening. Then he noticed that BGP was advertising a /20 address range while each NAT range was a /25 address range. A /24 address range is typically the smallest that can be advertised out to the internet, which made him look at BGP path selection. Was there a problem with ingress path selection? He had the customer request BGP configuration information from each ISP.
Sure enough, ISP2 had stopped honoring BGP community strings without informing its customers. Packets inbound from the internet to the customer could take either path. When packets destined to the wired clients arrived via ISP2, they had to take another hop across the WAN from SW2 to SW1, slightly delaying those packets. The added latency caused the real-time streaming packets to arrive too late for playback in the real-time applications. The effect within real-time applications is identical to packet loss, resulting in the pixilation of video and garbled audio that was being reported.
Conclusion
Fortunately, there was a simple solution. Bickham recommended that the customer change to an active/backup BGP configuration in which ISP1 was the primary path for all clients and the ISP2 path as a backup. This change worked!
The correct diagnosis of the problem required a system-level perspective instead of a device’s packet handling perspective. The problem’s origin was outside the customer’s network, so examining changes in their network would never have found the problem.
Copyright © 2022 IDG Communications, Inc.
